作者:0xhhh,EthStorage|PolygonzkEVM的整体架构和交易执行流程),我们总结了PolygonzkEVM的整体框架以及交易执行流程,同时也分析了PolygonzkEVM是如何实现计算扩容的同时继承了L1的安全性的;在这篇文章里,我们将依托上篇文章建立的框架,深入polygonzkEVM关于Sequencer和Bridge更多的技术细节,同时也探讨未来潜在的去中心化Sequencer架构的不同特点。
一、深入解析zkEVMBridge
在上一篇文章里,我们介绍PloygonzkEVM的过程中,实际上缺失了很重要的一个部分,就是PolygonzkEVM的原生桥。1.跨链数据状态管理PolygonzkEVM在L1和L2分别维护了一棵ExitTree,名字分别为L1ExitMerkletree和L2ExitMerkletree。但是为了更好的管理这两棵树,PolygonzkEVM很聪明的将这两棵树结合在了一起,如下图:
也就是用分别把L1ExitTreeRoot作为GlobalExitTree的左叶子节点,把L2ExitTreeRoot作为GlobalExitTree的右叶子节点。不过需要注意这里L1TreeRoot和L2TreeRoot是SparseMerkleTree(SMT),而GlobalExitTree是BinaryMerkleTree。L1/L2ExitTree叶子节点的基本信息如下:

2.跨链流程
在PolygonzkEVM的合约设计中,还是尽可能的将Bridge和Consensus合约尽可能的解耦。目前其在L1部署的合约主要分为3个,如下图所示:
需要注意的是他们之间不是继承关系,都是独立的合约,PolygonZkEVMBridge和PolygonZkEVM都会调用PolygonZkEVMGlobalExitRoot来更新或验证GlobalExitTreeRoot。

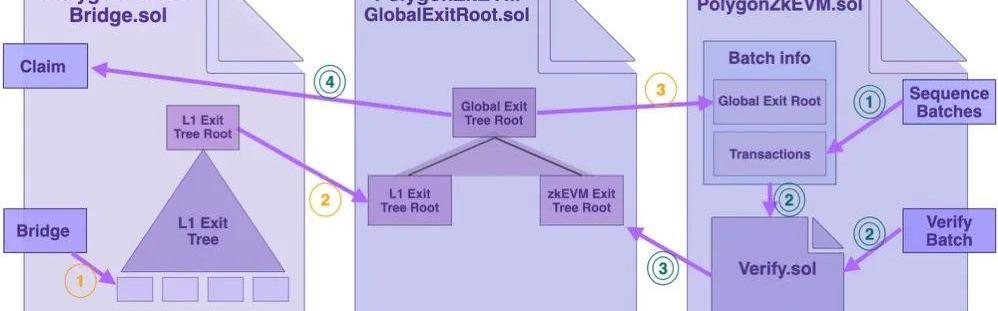
1)?L1→L2的跨链流程
L1→L2的跨链流程对应上图的橙色标识的三个步骤:

对应以下代码中的BatchData的结构体中的globalExitRoot:

PolygonZkEVMBridge在L2的合约
https://testnet-zkevm.polygonscan.com/tx/0x2a742f2f8a7b8635a76cc70b4574bebb1a81b2c0c1a618188773a1f8f2283bb8
https://testnetzkevm.polygonscan.com/address/0x39e780d8800f7396e8b7530a8925b14025aedc77#code
2)L2→L1的跨链流程
用户调用部署在L2的Bridge合约(PolygonZkEVMBridge.sol)中的Bridge()函数发送一笔L2-Bridge-Tx,这会更新添加一个新节点在L2ExitTree中,然后依次更新L2ExitTreeRoot和GlobalExitTreeRoot。
接下来当Sequencer会把这笔L2-Bridge-Tx放到某一个Batch中发送到L1的共识和DA合约(PolygonZkEVM.sol)中。
然后在之后Aggregator调用trustedVerifyBatches()往L1提交validityproof的时候,实际上也会把L2ExitRoot也一并作为Input进行上传,也就是以下函数的中的NewLocalExitRoot,它代表了L2有新的BridgeToL1的交易,但是这些交易目前在L1还不能提款,需要等待这个新的NewLocalExitRoot被验证成功。
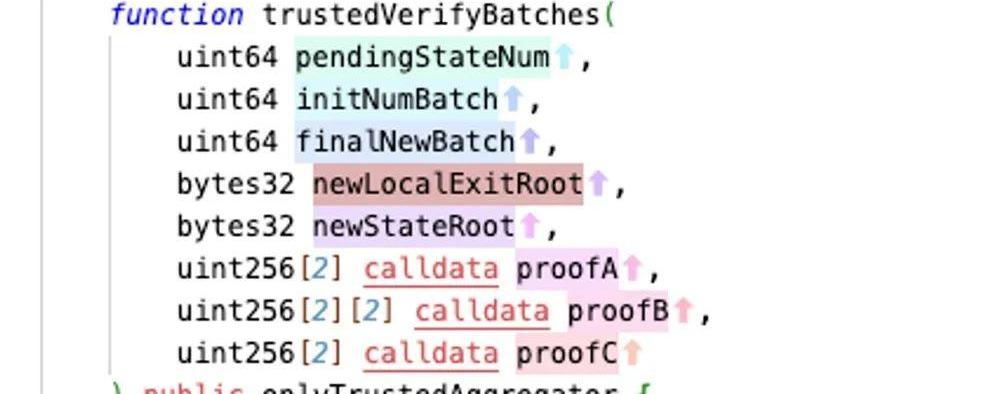
接下来这个传入的NewLocalExitRoot也会作为验证电路的一部分,输入这个验证逻辑是我在L2发生的这些新的BridgeToL1的交易是不是导致L2ExitTreeRoot变成当前这个提交的NewLocalExitRoot。
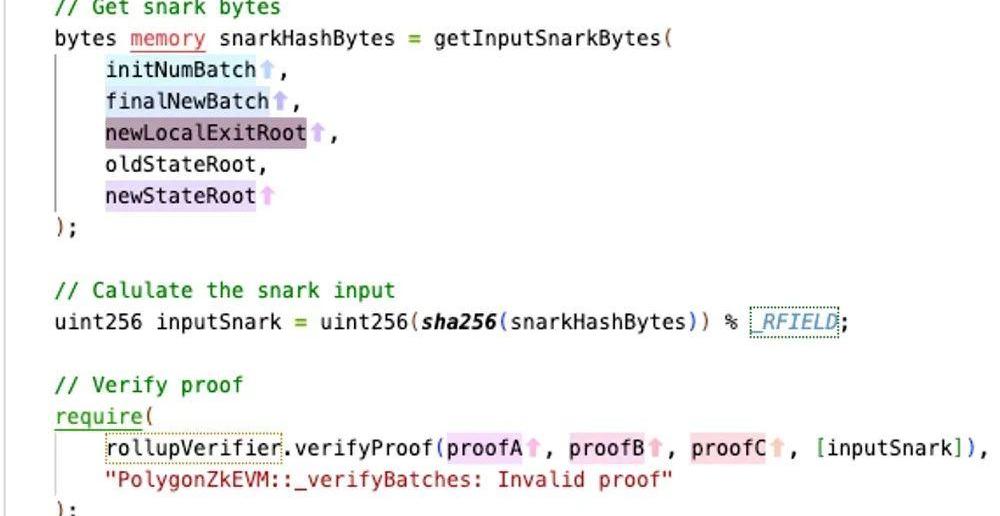
如果这个这个ValidityProof验证通过,那么L1的GlobalExitRootManager会更新L2ExittrreRoot和GlobalExitTreeRoot:?globalExitRootManager.updateExitRoot(newLocalExitRoot);
这个时候,用户就可以调用部署在L1的Bridge合约(PolygonZkEVMBridge.sol)的ClaimAsset()函数并给出相应的MerklePath进行提款,跨链交易的也就完美结束。
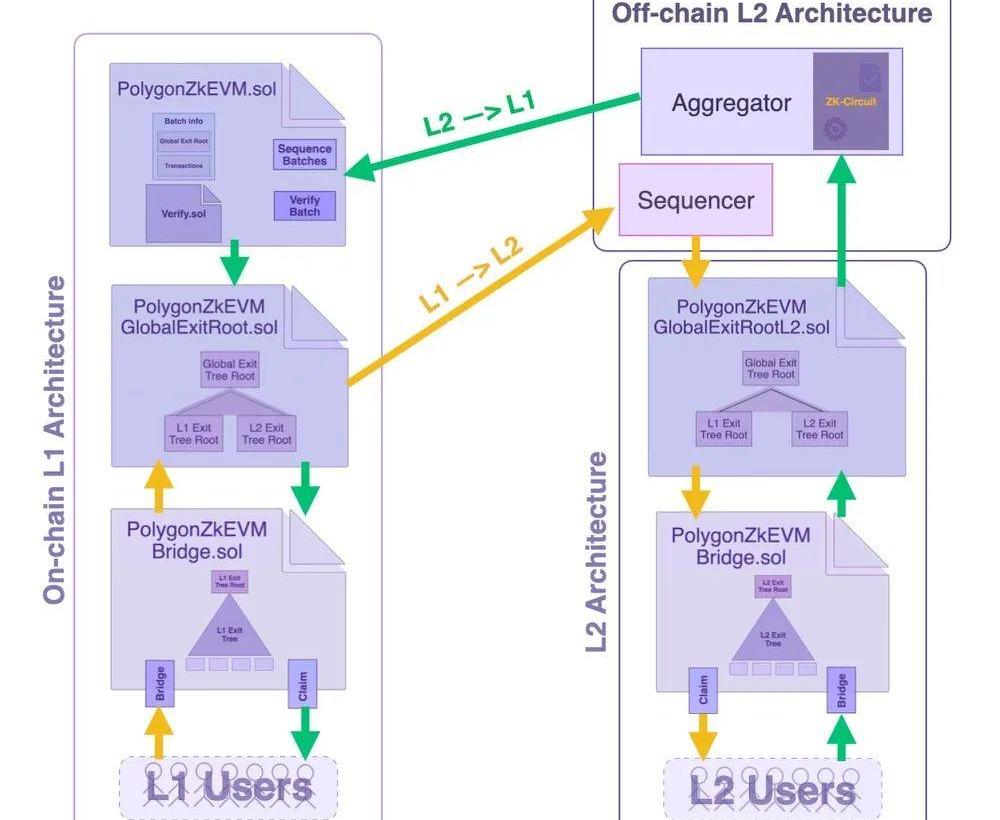
二、PolygonzkEVM如何抗审查
在上篇文章,我们介绍了TrustedSequencer,由官方运行的SingleSequencer,基本上L2网络的交易都会提交给这个TrustedSequencer,并且可以获得一个及时SequencerFinality。
而实际上用户还可以通过另一种方式直接提交交易到L1的合约中,而不需要通过TrustedSequencer,从而保证了整个网络仍然具备一定的抗审查的特性。
1.执行流程
1)用户调用L1合约中的ForceBatch函数,通过这个函数可以用户可以把自己想要执行的L2交易直接送到L1的合约中的。

2)合约中会将这些Transactions打包成一个Batch,并且记录在合约中一个ForceBatches的Mapping中。

3)TrustedSequence监听到ForceBatches中有新的ForceBatch的时候,会将其同步到本地的节点中,然后会在下次往L1提交Batches的时候包含这个ForceBatch。
4)不过这里还存在一种特殊情况,如果TrustedSequence如果宕机了,或者故意不提交某个用户提交的ForceBatch,那么在五天之后用户可以自己调用L1合约中的SequenceForceBatches()函数,让这笔ForceBatch进入到L1合约中的SequencedBatches,也就意味着这笔ForceBatch在Rollup中的交易顺序被L1合约最终确定,即便是TrustedSequence也无法再更改这个ForceBatch的交易顺序。(实际上所有Rollup都会有这样的特性来提供抗审查特性比如Arbitrum的SequenceInbox和Inbox)。
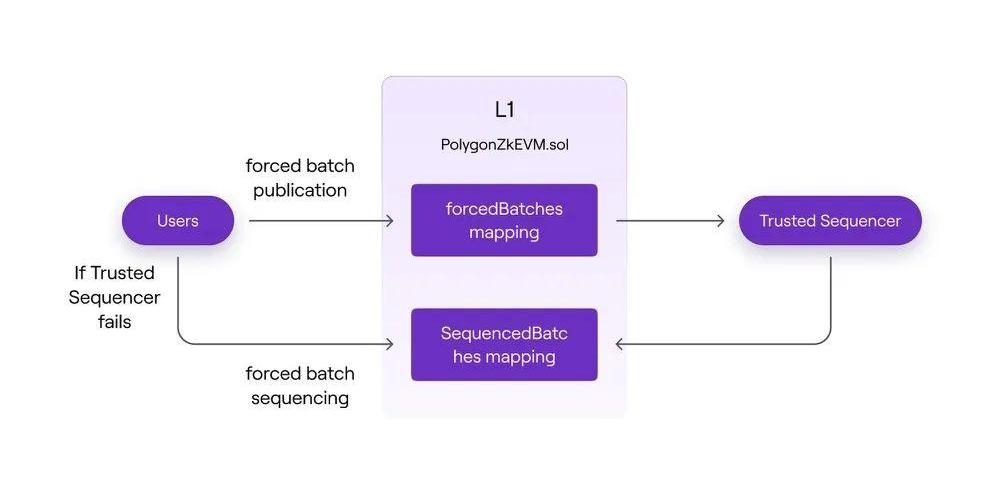
不过这里推荐大家尽可能不要通过ForceBatch的方式提交Rollup的交易,因为通过这种方式,你在调用ForceBatch往L1提交自己的交易的时候会暴露你的交易内容,而这个时候交易顺序还没被确认(需要等待Sequence同步ForceBatch并通过SequenceBatch()再一次提交到L1的时候交易顺序才被真正确认)同时你已经没办法取消你的交易了,这个时候你有很大的可能被抢跑。
这似乎这并不能真正的抗审查,因为ForceBatch的方式存在被抢跑的风险,用户真的会用这个功能吗?
2.Sequencer的真正状态
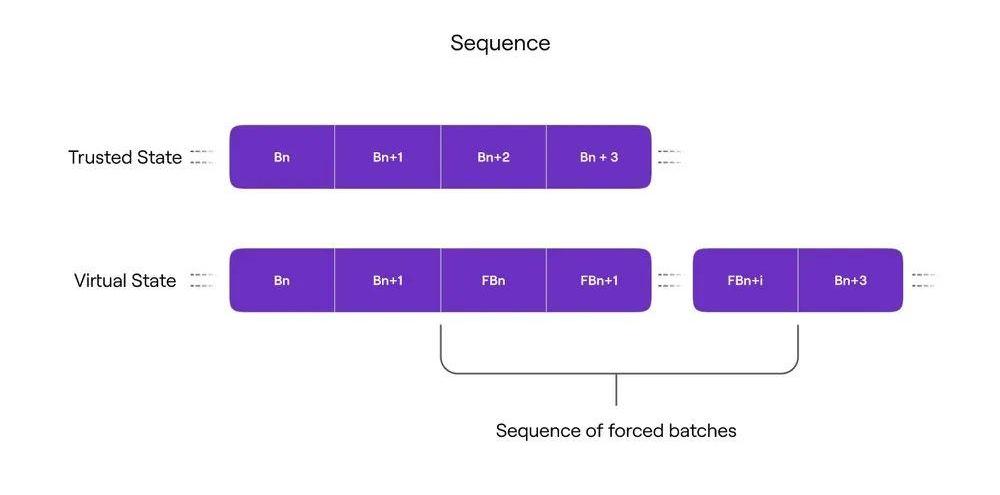
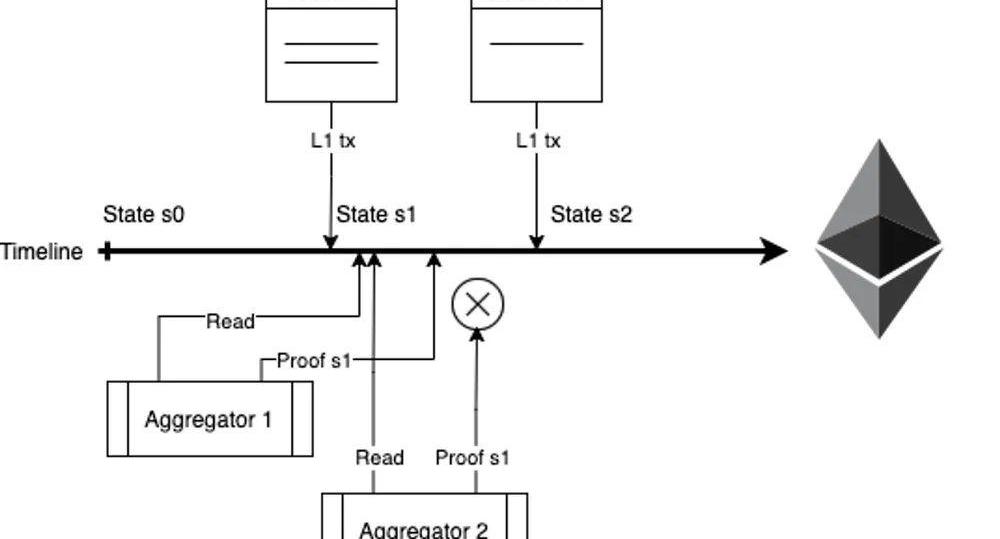
从上文我们可以得知,Sequence会从L1同步ForceBatch中的交易到本地节点进行执行,于是Sequence的真正状态如下图所示:
Bn表示用户直接提交给Sequence的交易执行后得出的结果;
FBn表示Sequence同步ForceBatch的交易进行执行后得出的结果。
https://zkevm.polygon.technology/
三、L2网络存在的三种不同的Finality
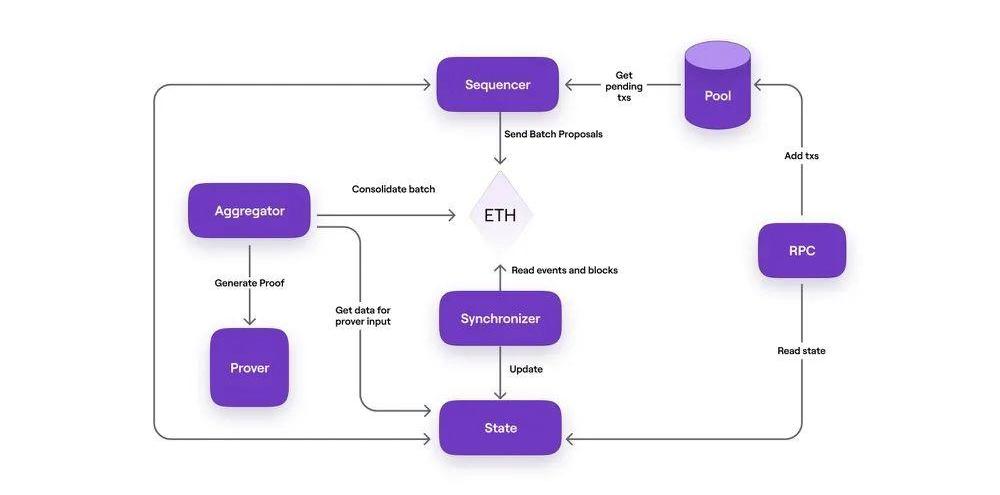
接下来我们回顾下Ploygon的整体架构,为接下来的去中心化Sequencer思考做好铺垫。我们需要关注到。
对于Sequencer和Aggregator来说,他们的状态都是通过Syschronizer从一层合约中进行同步的,他们之间并不是直接通信的。
1)三种Finality
因此我们可以认为目前整个网络存在三种不同程度的Finality,我们给它命名成SequencerFinality,DAFinality和Verified?Finality。
a.第一种SequecerFinality,在有一些文章中也将这种Finality称为SoftFinality,但是我觉得叫做SequenecerFinality更为合适,因为这个Finality其实是SingleSequencer给的状态承诺。
Sequencer接受到用户交易之后,执行后给出的状态,这是最不安全的状态;但是在目前官方SingleSequencer的场景下,却可以在保证安全的同时带来极致的用户体验。在目前单一Sequencer的Rollup网络中,基本上都可以体验到即时确认的快乐。不过,SingleSequencer最大的风险就是Sequencer宕机,这会导致整个L2网络基本瘫痪,不过由于DA层是位于以太坊上的,依然可以在之后部分恢复L2网络宕机前的状态;不过那部分来不及发送到L1的L2交易将无法被恢复。
b.第二种DAFinality,代表这些交易已经被提交到L1的DA层合约上,此时交易顺序也被确定了。
TrustedSequencer已经调用SequenceBatch将交易发送到L1上,在这种情况下,交易已经被DA层包含;在Polygon的设计中,由于单一TrustedSequencer的原因,所以可以确保上传到L1合约上进行DA的交易都是有效交易。我们可以认为当一笔交易被TrustedSequencer上传到L1合约中的时候,这个时候它已经被Rollup网络承认了,并且在之后Aggregator会提供ValidityProof让这笔交易真正无法被Revert(除非L1Reorg)。
c.第三种VerifiedFinality指的是这笔交易已经通过ValidityProof的验证了,属于真正的Finality;在一些文章中也把它叫做HardFinality。
当Aggregator为一批上传到DA层的交易提供的ValidityProof被合约验证通过的时候,这个时候我们认为这些交易已经无法被Revert了(除非L1Reorg)。我们在上一篇文章里提到过,目前提交到DA层的交易到验证validityproof的通过的时间是30分钟,同时Aggregator也可以通过提供ValidityProof从而获得足够的Matic报酬。
2)Aggregator同步状态的取舍
假如我们这里假设提供ValidityProof是有利可图的,那么对于Aggregator来说,最好的同步交易的方式,不是在L1的DA层合约中同步,而是直接跟TrustedSequencer建立rpc链接,直接从TrustedSequencer获取最新的交易,这样生成ValidityProof会更快,从而相比其他从DA合约中获取交易的Aggregator更有竞争优势,因为提供ValidityProof这件事情是先到先得,对于一批交易来说也仅仅需要一个聚合的validityproof,第一个提交ValidityProof的Aggregator可以拿走对应交易的Matic奖励,其他Aggregator生成的ValidityProof也无法再获得任何奖励。
不过目前实际上Polygon跟TrustedSequencer角色一样,也有一个TrustedAggregator,来处理生成和提交ValidityProof的工作。https://zkevm.polygon.technology/
四、Sequencer的未来
接下来,我们继续是关于去中心化Sequencer的思考。首先第一个问题是我们为什么需要去中心化的Sequencer?因为我们希望Rollup能在扩容以太坊的计算能力的同时,继承以太坊的安全性和去中心化程度。而当前SingleSequencer的方案显然达不到继承以太坊的去中心化程度的目标。再继续勾画去中心化Sequencer的未来之前,我们先来回顾Sequencer的工作。以PolygonzkEVM为例,目前TrustedSequencer对交易的处理会遵循FCFS,先到的交易先进行处理,并行Mempool也是私有的,尽可能保护用户的交易不被MEV。
当收集到一定量的交易之后,会把它们封装成Batches上传到L1合约中对应的DA的位置,并且在第一篇文章中我们也提到了这些了Sequencer上传的Batch中实际上已经通过在后一个Batch包含前一个Batch的哈希的方式确定了交易的顺序。因此我们认为Sequencer的工作类似L1Proposer的工作,提议了一批交易,并且确认了交易的顺序。
因为我们是从PolygonzkEVM开始介绍去中心化Sequencer的,我们就先介绍PolygonzkEVM的去中心化Sequencer方案ProofOfEfficiency(效率证明)。
1.Proof-0f-Efficiency?1)方案描述在POE的设计中,允许任何人成为Sequencer并且向L1提交RollupBlock的,Rollup网络的交易顺序取决于交易被提交到L1的RollupDA合约的顺序。如下图,用户都可以自行选择将交易发送给哪个Sequencer,甚至可以自己成为Sequencer,这些Sequencer在收到足够的交易之后,会将这些交易打包成Batch,然后往L1上提交。
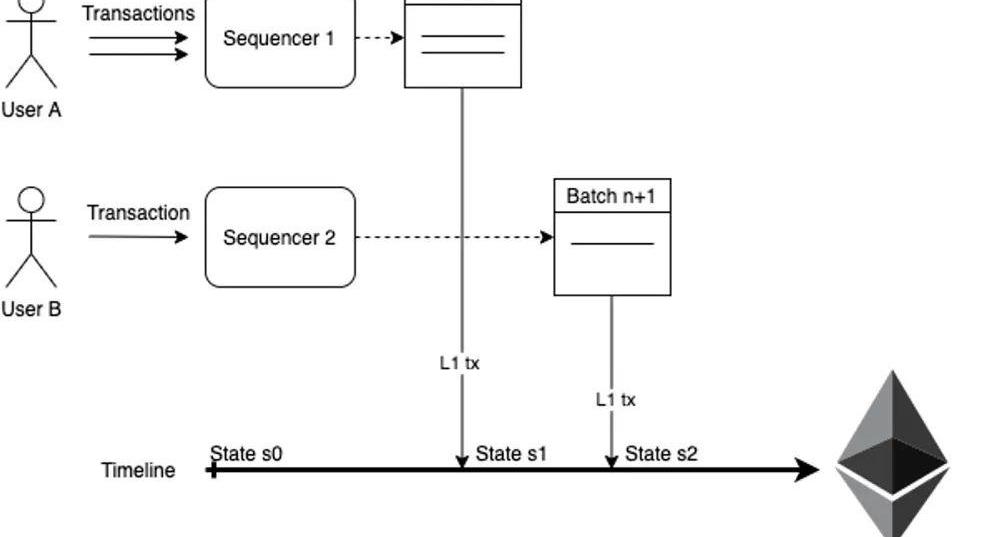
这些Sequencer需要考虑利润问题:
Sequencer成本=L1gascost?+generatezkProoffee
Sequencer收入=L2gasfee
所以Sequencer需要考量将至少多少笔交易打成一个Batch提交L1才是有利可图的。但是Sequencer还需要考虑另外一个问题,时效性问题,如果一个Sequencer的提交交易速度过慢,那么它的用户可能会流失到其他提供更快确认的Sequencer那里。
2)方案可行性
首先这个方案能运转的核心原因是Polygon的DA部分没有做任何状态承诺,仅仅确定了交易顺序;状态承诺(Sequencer承诺交易执行后对应的新的世界状态,但是这个状态未被ValidityProof或者FraudProof验证的状态)是在提交ValidityProof的时候才会给出,这是这个方案能执行的核心原因。
实际上像Arbitrum在提交交易到DA合约中的时候也没有做任何状态承诺,但是Optimism在提交交易到DA层的时候是携带状态承诺的,所以理论上Arbitrum也可以运用POE来实现去中心化Sequencer,但是Optimism则不行。
3)为什么携带状态承诺就不能运用POE?因为在多个Sequencer几乎同时往L1提交Batch的时候,实际上没有一个Sequencer可以保证最终在DA合约上L2的交易顺序到底是怎样,所以如果携带状态承诺,大概率会导致整个Batch无法通过ValidityProof或者FraudProof的验证。
4)如何处理无效交易?
无效交易指的是比如账户的Nonce过低,账户余额不足以支付Gas费用的交易,当这些交易在L1(Geth)是不会被放入到区块的,因为如果一个区块中包含一笔无效交易,都会导致整个区块变成无效区块,Validator不会给这种区块投票,Propoer也不会提案这种区块。
在当前SingleSequencer的情况下,L2网络是有能力辨别这种无效区块的,并且可以避免在L1DA合约中避免包含这种交易,这可以避免浪费L1的区块空间。
但是采用POE之后,Sequencer实际上失去了辨别这种无效交易的能力,因此在L1的验证交易带来的状态变更过程中,也需要将这种情况考虑进去,并且Sequencer提交无效交易是无法获得用户的手续费的。
5)PublicMempool(公共交易池)?
采用POE之后,如果这些去中心化的Sequencer之间会存在PublicMempool,那么会导致用户一笔交易被不同的Sequencer提交多次,当然只有第一次提交的交易是有效交易,也只有这交易最终能获得用户的手续费。
6)Sequencer为何无法预测执行结果
在这种PermissonlessSequencer的模型下,一个Sequencer是无法给用户提供及时的SequencerFinality,因为Sequencer预测的最终上链的的交易顺序和实际的交易顺序会有偏差,这个偏差是由于可能有多个Sequencer在几乎同个时刻向L1的DA合约提交了交易Batch,在这种情况下很难保证这些交易Batch的实际顺序是否跟预测顺序相同。
因此Sequencer同步自身状态的时候,也会从L1的DA合约上同步最新被提交的交易Batch并执行来获得最新状态,而不是其他Sequencer那里同步状态。
7)L2的MEV流失到L1
由于交易任何人都可以成为Sequencer提交Rollup网络的交易,并且提交交易Batch的交易实际上跟L1的普通交易无异,因此它实际上还是会经过MEVBoost的整个流程,意味着L2网络的MEV都会流失到MEVBoost模块。
8)Aggregator的设计
在POE的设计上,Aggregator同样也是Permissionless的,但是由于ValidityProof实际上只需要一个正确的交易,也就意味着只有第一个为交易提交正确的ValidityProof的Aggregator才能获得奖励。因此作为Aggregator,你需要权衡提交的ValidityProof的证明范围,提交时间以及提交ValidityProof可以获得的Matic奖励之间的关系,最终找出一个最有竞争力的策略。
似乎,利用这种自由市场竞争策略,可以让交易对应的ValidityProof的生成速度达到最快。
https://ethresear.ch/t/proof-of-efficiency-a-new-consensus-mechanism-for-zk-rollups/119888)
8)总结
POE可以带来完全PermissionLess的网络,并且整个网络可能也不会有宕机的风险,但是L1的DA合约中可能包含无效交易(比如相同Nonce的交易),MEV都被L1网络获取,并且只能提供DAFinality和VerifiedFinality。
2.BasedRollup
BasedRollup是期望将Rollup网络的SingleSequencer的工作委托给以太坊的proposer去完成。它会要求每个Proposer提案L1的区块需要包含一个有效的Rollup区块。
因此L1网络的BlockBuilder需要运行一个Rollup的全节点用来接受L2的交易,并且构建最大价值的RollupBlock。
这样的方案的好处是可以最大程度的继承了L1的安全性以及去中心化程度,但是也会导致只能提供SequencerFinality和VerifiedFinality,L2的MEV也会都流失到L1同时也需要对以太坊客户端的代码进行修改,这也可能会影响L1的安全性。
3.ShareSequencing
SharedRollup相比BasedRollup将构建和提交RollupBlock的工作交给以太坊的Propoer,则是将这个工作交给ShareSequencers中的委员会。
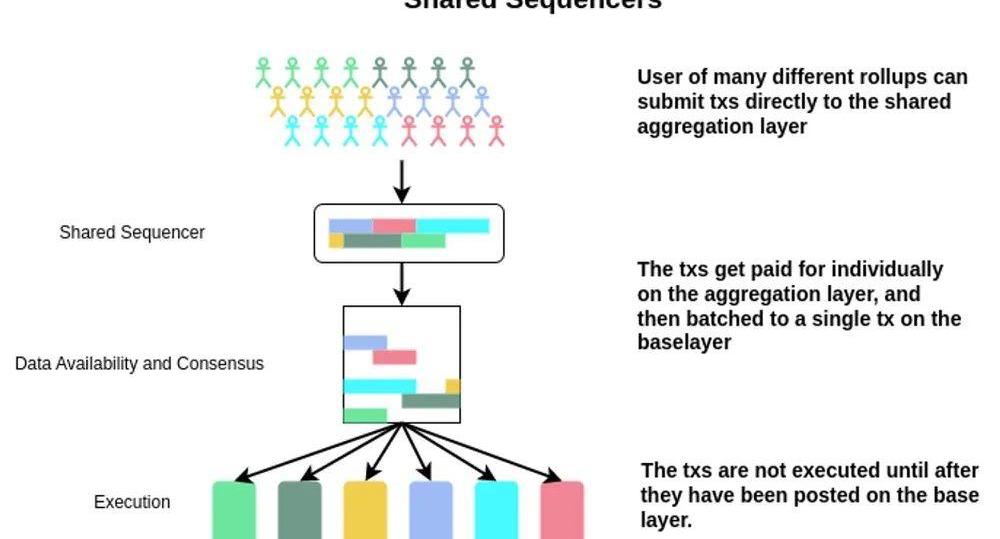
3.1.具体流程如下:
a.不同Rollup的用户都可以直接向SharedSequencers所在的网络直接发送Rollup的交易b.SharedSequencers会在内部运行一个BFT共识,在每一轮选出一个SequencerLeader来对交易进行排序并构建对应的RollupBlock.
c.然后将这些RollupBlock提交到不同的Rollup网络对应在L1上的DA合约
d.不同的Rollup网络再通过L1的DA合约同步网络中的最新交易,然后进入到他们自身验证ValidityProof或者FraudProof的流程。
3.2.SharedSequencer架构的潜在影响
1)多个Rollup网络共用一个SharedSequencerCommittee
2)从单个Rollup的角度来看,只是把把官方运行的SingleSequencer委托给了这个SharedSequencerCommittee
3)在每一轮从SharedSequencerCommittee中会选出一个SequencerLeader,负责对接入这个SharedSequencers网络的RollupBlock进行构建,并且依次将这些RollupBlock提交到对应Rollup在以太坊上的DA合约内。
a.比如A需要将Arbitrum上USDC跨链到Optimism上,那么正常流程是它会在Arbitrum上先进行Lock,等待Lock成功之后,再去Optimism上提交自己在Arbitrum的LockProof(e.g.MerkleTreePath+TreeRoot),然后在Optimism上Mint出来对应的USDC资产;
b.当用户向SharedSequencers提交这样一个交易的时候,每一轮的SeuqnecerLeader实际上可以将ArbitrumLock的操作+OptimismMint的操作放在同一时刻的RollupBlock进行执行,这样可以带来巨大的用户体验提升;
c.但是它依旧无法做到像同一个Rollup网络的用户体验,比如Mint的时候你依然需要提供你的LockProof;
d.所以我们可以认为接入到这个SharedSequencers网络中的Rollup们是一个接近于完全同步的系统;
e.接近完全同步的系统有什么作用呢?f.可以提供原子跨链服务,因为每一轮选出的SequencerLeader拥有排序所有Rollup交易的权力,所以他有能力构建原子跨链的交易。
4)跨链MEV的角度
因为每一轮的LeaderSequencer拥有所有RollupBlock的排序权力,所以理论上可以捕获所有的跨链MEV,感觉之后SharedSequencer也需要引入或者直接接入MEVBoost这种MEV架构,因为从目前看各个Rollup网络的区块间隔都会远远快于以太坊的区块间隔,比如Optimism的2s每一块,Arbitrum最快是0.25s出一块。因此作为每一轮的SequencerLeader构造RollupBlock的计算量其实并不小,因此感觉生态成熟起来之后也会有相应的MEV架构来辅助构造最大价值的RollupBlock。
5)从Decentralization和Liveness的角度看SharedSequencers
因为SharedSequencerCommittee内部会用BFT共识来在每一轮选择出一个SequencerLeader来提案所有的RollupBlock,所以Decentralization和Liveness都要比目前的SingleSequencer方案强大不少。
6)从生态的角度
a.对于不同的Rollup拥有了更好的共存的理由,因为用户可以很方便的在各个Rollup的网络中进行资产转移,也可以更好的对实现以太坊生态的负载均衡。
b.对于不同的正在构造ShreadSequencer的项目而言,可能就是你死我活的竞争,因为从用户角度和目前各个Rollup都是SignleSequencer的角度而言,似乎在SharedSequencer这条赛道会出现赢家通吃的问题。
7)Finality角度
因为本质上还是SingleSequencer,所以无论是SequencerFinality还是VerifiedFinality都跟原来是一样的。
3.3.潜在风险
因为Rollup之间不一定是同构Rollup,比如Arbitrum和polygonzkEVM之间的跨链,那么意味着跨链交易对应在Arbitrum和polygonzkEVM之上交易的VerifiedFinality并不一致,比如我在PolygonzkEVM之上的mint交易已经获得VerifiedFinality(提交了ValidityProof),但是此时我在Arbitrum上的Lock交易仅获得了DAFinality(需要等待7天挑战期),如果我在这个时候成功Revert了我在Arbiturm的交易,那么也就意味着:我实际上在PolygonzkEVM无成本铸造了很多跨链资产。
3.4总结
优势:
a.MEV可以被Rollup网络获取,并且还可以额外获取更多的跨链MEV;
b.用户跨Rollup体验好,并且能让Rollup之间由竞争关系转为共生关系,每个Rollup都可以提供自己独特的价值,然后与其他Rollup网络组合成可以为用户提供各种各样定制化服务的网络;
c.相比SignleSequencer,网络的去中心化程度得到了大幅度增强,并且网络的稳定性大大增强了,在某一个SequencerLeader不出块的时候,会及时轮换一个新的SequencerLeader进行出块;
d.网络的三种Finality都跟原来SingleSequencer保持一致。劣势:本质上还是SingleSequencer的模型,并且也引入了新的攻击向量。
五、总结
在这篇文章我们详细结构了PolygonzkEVM的bridge以及Sequencer更多的技术细节,在下篇文章也是最后一篇文章,会继续解剖zkEVM的技术细节,敬请期待。
来源:FlipResearch推文编译:Biteye核心贡献者Crush$ARB空投可能是今年最热门的空投之一.
作者:西柚,ChainCatcher3天内,Avalanche链上出现两次停止出块60分钟以上的状况,原定于3月30日的Cortina升级由于网络不稳问题被延迟至4月6日执行.
作者:西柚,ChainCatcher2023年4月4日凌晨,推特网页端用户的官方主页键上方不再是以往的蓝色小鸟推特标志,改为了一个柴犬的卡通头像.
撰文:十文,Odaily最近三天,两位?NFT?OG「Franklin」和「麻吉大哥」黄立成相继宣布退出NFT领域.
作者:CoinW? 4月26日,Consensus2023byCoinDesk拉开序幕,CoinW作为本届共识大会深度合作伙伴,从签到处背景墙到扶梯以及展台,随处可见CoinW的品牌元素.
作者:RebeccaLeeNFT诞生,物理世界与虚拟世界的入口开启当前,NFT市场陷入了流动性不足,成交量下降的低迷态势.