
我们要感谢PolygonZero、Consensysgnark、PadoLabs和DelphinusLab团队对本篇文章的宝贵评论和反馈。零知识证明开发框架评测平台「万神殿Pantheon」
过去几个月,我们投入了大量时间和精力,开发了利用zk-SNARK简洁证明构建的前沿基础设施。这个次世代创新平台使开发者能够构建前所未有的区块链应用新范例。在开发工作中,我们测试并使用了多种零知识证明(ZKP)开发框架。虽然这段旅程收获颇丰,但我们也确实意识到,当新的开发者试图找到最适合其特定用例和性能要求的框架时,多种多样的ZKP框架通常会给他们带来挑战。考虑到这一痛点,我们认为需要一个能够提供全面性能测试结果的社区评估平台,这将极大地促进这些新应用的开发。为了满足这一需求,我们推出了零知识证明开发框架评测平台「万神殿Pantheon」这一公益社区倡议。倡议的第一步将鼓励社区分享各种ZKP框架的可复现性能测试结果。我们的最终目标是共同协作创建并维护一个广受认可的测试平台,评估低级电路开发框架、高级zkVM和编译器,甚至硬件加速提供商。我们希望这一举措能够让开发者们在选用框架时能有更多性能比较的参考,从而加快ZKP的推广。同时,我们希望通过提供一组普遍可参考的性能测试结果,促进ZKP框架本身的升级和迭代。我们将大力投入这项计划,并邀请所有志同道合的社区成员加入我们,共同为这项工作做出贡献!第一步:使用SHA-256对电路框架进行性能测试
在这篇文章中,我们迈出了构建ZKPPantheon的第一步,在一系列低级电路开发框架中使用SHA-256提供一组可复现的性能测试结果。虽然我们承认其他性能测试粒度和原语或许也是可行的,但我们选择SHA-256是因为它适用于广泛的ZKP用例,包括区块链系统、数字签名、zkDID等。另外值得一提的是,我们在自己的系统中也使用了SHA-256,所以这对我们来说也很方便!我们的性能测试评估了SHA-256在各种zk-SNARK和zk-STARK电路开发框架上的性能。通过比较,我们力求为开发者提供关于每个框架的效率和实用性的见解。我们的目标是,希望本次性能测试结果能够为开发者在选择最佳框架时提供参考,使之做出明智的决定。证明系统
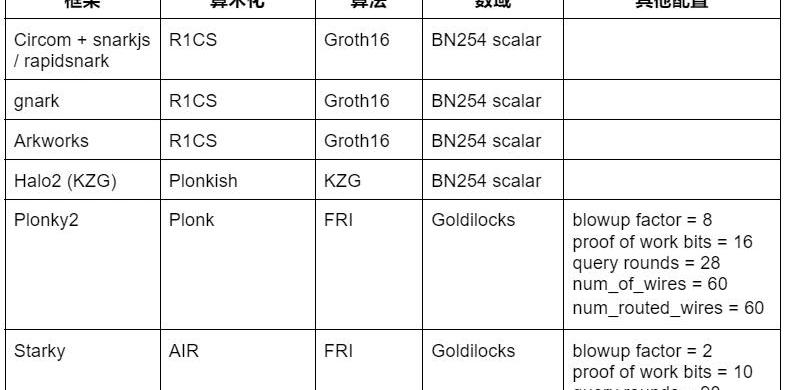
近年来,我们观察到零知识证明系统激增。跟上该领域所有激动人心的进步是具有挑战性的,我们根据成熟度和开发者采用情况精心挑选了以下证明系统作为测试对象。我们的目标是提供不同前端/后端组合的代表性样本。Circom+snarkjs/rapidsnark:Circom是一种流行的DSL,用于编写电路和生成R1CS约束,而snarkjs能够为Circom生成Groth16或Plonk证明。Rapidsnark也是Circom的证明器,它生成Groth16证明,并且由于使用了ADX扩展,它通常比snarkjs快得多,并尽可能并行化证明生成。gnark:gnark是来自Consensys的综合Golang框架,支持Groth16、Plonk和许多更高级的功能。Arkworks:Arkworks是一个用于zk-SNARKs的综合Rust框架。Halo2(KZG):Halo2是Zcash与Plonk的zk-SNARK实现。它配备了高度灵活的Plonkish算术,支持许多有用的原语,例如自定义网关和查找表。我们使用具有以太坊基金会和Scroll支持的KZG的Halo2分叉。Plonky2:Plonky2是基于来自PolygonZero的PLONK和FRI技术的SNARK实现。Plonky2使用小的Goldilocks字段并支持高效的递归。在我们的性能测试中,我们以100位推测的安全性为目标,并使用为性能测试工作产生最佳证明时间的参数。具体来说,我们使用了28Merkle查询、8的放大系数和16位工作量证明挑战。此外,我们设置num_of_wires=60和num_routed_wires=60。Starky:Starky是PolygonZero的高性能STARK框架。在我们的性能测试中,我们以100位推测的安全性为目标,并使用产生最佳证明时间的参数。具体来说,我们使用了90Merkle查询、2倍放大系数和10位工作量证明挑战。下表总结了上述框架以及我们性能测试中使用的相关配置。这个列表绝不是详尽的,我们还将在未来研究许多最先进的框架/技术。请注意,这些性能测试结果仅适用于电路开发框架。我们计划在未来发布一篇单独的文章,对不同的zkVM和IR编译器框架进行性能测试。
性能评测方法论为了对这些不同的证明系统进行性能测试,我们计算了N字节数据的SHA-256哈希值,其中我们对N=64、128、...、64K进行了实验。可以在此存储库中找到性能代码和SHA-256电路配置。此外,我们使用以下性能指标对每个系统进行了性能测试:证明生成时间证明生成期间的内存使用峰值证明生成期间的平均CPU使用率百分比。请注意,我们正在对证明大小和证明验证成本做一些“随意”的假设,因为这些方面可以通过在上链之前与Groth16或KZG组合来减轻。机器
我们在两台不同的机器上进行了性能测试:Linux服务器:20核@2.3GHz,384GB内存MacbookM1Pro:10核@3.2Ghz,16GB内存Linux服务器用于模拟CPU核数多、内存充裕的场景。而通常用于研发的MacbookM1Pro拥有更强大的CPU,但内核较少。我们启用了可选的多线程,但我们没有在此性能测试中使用GPU加速。我们计划在未来进行GPU性能测试。性能评测结果
约束数量在我们继续讨论详细的性能测试结果之前,首先通过查看每个证明系统中的约束数量来了解SHA-256的复杂性是很有用的。重要的是要注意不能直接比较不同算术方案中的约束数量。下面的结果对应64KB的原像尺寸。虽然结果可能因其他原像尺寸而异,但它们可以粗略地线性缩放。Circom、gnark、Arkworks都使用相同的R1CS算法,计算64KBSHA-256的R1CS约束数量大致在30M到45M之间。Circom、gnark和Arkworks之间的差异可能是由于配置差异造成的。Halo2和Plonky2都使用Plonkish算术,其中行数范围从2^22到2^23。由于使用查找表,Halo2的SHA-256实现效率比Plonky2的高得多。Starky使用AIR算法,其中执行跟踪表需要2^16个转换步骤。

证明生成时间使用Linux服务器测试了SHA-256的每个框架在各种原图像尺寸上的证明生成时间。我们可以得到以下发现:对于SHA-256,Groth16框架生成证明的速度比Plonk框架快。这是因为SHA-256主要由位运算组成,其中线值为0或1。对于Groth16,这减少了从椭圆曲线标量乘法到椭圆曲线点加法的大部分计算。但是,连线值并不直接用于Plonk的计算,因此SHA-256中的特殊连线结构不会减少Plonk框架中所需的计算量。在所有Groth16框架中,gnark和rapidsnark比Arkworks和snarkjs快5到10倍。这要归功于它们利用多个内核并行化生成证明的卓越能力。Gnark比rapidsnark快25%。对于Plonk框架,当使用>=4KB的较大原像尺寸时,Plonky2的SHA-256比Halo2的慢50%。这是因为Halo2的实现主要使用查找表来加速按位运算,导致行数比Plonky2少2倍。但是,如果我们比较具有相同行数的Plonky2和Halo2,Plonky2比Halo2快50%。如果我们在Plonky2中使用查找表实现SHA-256,我们应该期望Plonky2比Halo2更快,尽管Plonky2的证明尺寸更大。另一方面,当输入原像尺寸较小时,由于查找表的固定设置成本占大部分约束,Halo2比Plonky2慢。然而,随着原像的增加,Halo2的性能变得更具竞争力,对于高达2KB的原像大小,其证明生成时间保持不变,如图所示,其几乎呈线性扩展。正如预期的那样,Starky的证明生成时间比任何SNARK框架都短得多(5倍-50倍),但这是以更大的证明大小为代价的。另外需要注意的是,即使电路大小与原像大小成线性关系,由于O(nlogn)FFT,对于SNARKs的证明生成也是呈超线性增长的。
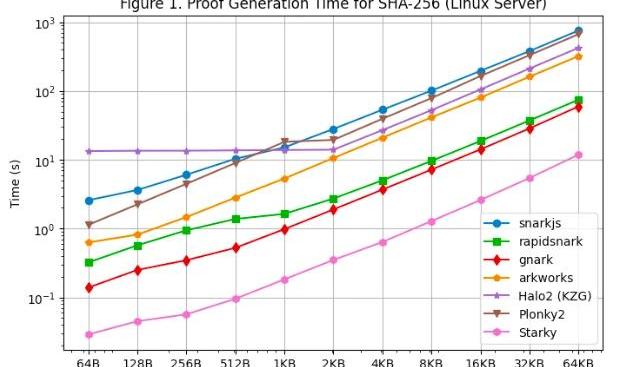
我们还在MacbookM1Pro上进行了证明生成时间性能测试,如所示。但是,需要注意的是,由于缺乏对arm64架构的支持,rapidsnark未包含在该性能测试中。为了在arm64上使用snarkjs,我们必须使用webassembly生成见证,这比Linux服务器上使用的C++见证生成要慢。在MacbookM1Pro上运行性能测试时还有几个额外的观察结果:除了Starky之外,所有SNARK框架在原像尺寸变大时都会遇到内存不足(OOM)错误或使用交换内存现象。具体来说,Groth16框架在原像尺寸>=8KB时就开始使用交换内存,而gnark在原像尺寸>=64KB时出现内存不足。当原像尺寸>=32KB时,Halo2遇到了内存限制。当原像尺寸>=8KB时,Plonky2开始使用交换内存。基于FRI的框架在MacbookM1Pro上比在Linux服务器上快大约60%,而其他框架在两台机器上面的证明时间相似。因此即使在Plonky2中没有使用查找表,它在MacbookM1Pro上实现了与Halo2几乎相同的证明时间。主要原因是MacbookM1Pro拥有更强大的CPU,但内核更少。FRI主要进行哈希运算,对CPU时钟周期比较敏感,但并行性不如KZG或Groth16。

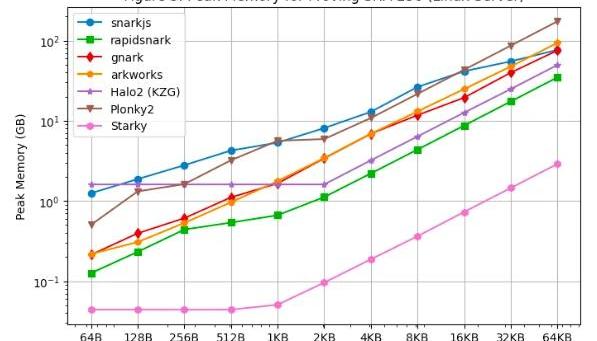
内存使用峰值
和分别显示了在LinuxServer和MacbookM1Pro上生成证明期间的内存使用峰值。根据这些性能测试结果可以得出以下观察结果:在所有SNARK框架中,rapidsnark是内存效率最高的。我们还看到,由于查找表的固定设置成本,当原像尺寸较小时,Halo2使用更多内存,但当原像尺寸较大时,整体消耗的内存较少。Starky的内存效率比SNARK框架高10倍以上。部分原因是它使用了更少的行。应该注意的是,由于使用交换内存,原像尺寸变大,因此MacbookM1Pro上的内存使用量峰值保持相对平稳。

CPU利用率
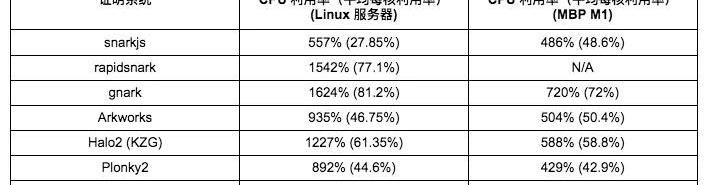
我们通过测量SHA-256在4KB原像输入的证明生成期间的平均CPU利用率来评估每个证明系统的并行化程度。下表显示了LinuxServer和MacbookM1Pro上的平均CPU利用率可能难以有效地使用多核,但它们在我们的性能测试中的表现并不比某些Groth16或KZG框架差。在具有更多内核的机器上,CPU利用率是否会有差异还有待观察。
结论及未来研究
这篇文章全面比较了SHA-256在各种zk-SNARK和zk-STARK开发框架上的性能测试结果。通过比较,我们深入了解了每种框架的效率和实用性,以期可以帮助需要为SHA-256操作生成简洁证明的开发者。我们发现Groth16框架在生成证明方面比Plonk框架更快。Plonkish算术化中的查找表在使用较大的原像尺寸时显着减少了SHA-256的约束和证明时间。此外,gnark和rapidsnark展示了利用多核以并行化运作的出色能力。另一方面,Starky的证明生成时间要短得多,但代价是证明大小要大得多。在内存效率方面,rapidsnark和Starky优于其他框架。作为构建零知识证明评测平台「万神殿Pantheon」的第一步,我们承认本次性能测试结果远不足以成为最终我们希望构建的一个综合测试平台。我们欢迎并乐于接受反馈和批评,并邀请所有人为这项倡议做出贡献,以便开发者更容易、低门槛地使用零知识证明。我们也愿意为个人独立贡献者提供资助,以支付大规模性能测试的计算资源成本。我们希望可以共同提高ZKP的效率和实用性,更为广泛地造福社区。最后,我们要感谢PolygonZero团队、Consensys的gnark团队、PadoLabs以及DelphinusLab团队,感谢他们对性能测试结果的宝贵审查和反馈。
一周前还难以想象,2023年第一个带来加密市场恐慌的会是号称最合规的稳定币发行商Circle。上周末,美国硅谷银行破产危机,连带着加密稳定币USDC脱锚,一度跌至0.87美元,最终引发市场恐慌性.
本文为iZUMiFinance联合创始人JimmyYin于3月3日在Denver活动上的演讲,经编译整理如下.
原文标题:TheRoyaltyWars原文来源:Decentralised.co原文作者:Joel&Siddharth原文编译:Kxp.
本篇文章属于MintVentures的MintClips系列。MintClips是我们对于行业事件,在内外部交流后的一些思考.
ARB申领将于区块高度16890400开放,根据区块倒计时,预计对应北京时间为本周四晚上。有部分科学家已经「提前抢跑」,因为根据往期空投经验,fomo情绪会在Token开放交易早期将币价拉高.
KuCoinLabs首期孵化计划“TheAstroSelection”成功举办线上DemoDay。该计划为期八周,提供来自强大导师阵容和丰富行业网络的全方位指导.