前言:隐私计算赛道作为当下的风口赛道,无数企业纷纷涌入,抢跑占道。作为一家专注于区块链隐私计算赛道科普入门的垂直媒体,同时也是针对隐私计算兴趣者开放的“纯天然”、低门槛入口,我们汇总并分类了隐私计算行业内晦涩难懂的名词,编写了「隐私计算词典」板块,帮助大家理解、学习。?
此篇,我们来了解隐私计算技术架构的第三部分——联邦学习。
近年来,从无人驾驶汽车,到AlphaGo击败顶尖的真人围棋手等等,AI人工智能在科技领域的发展着实吸引了足够多人的眼球。
然而,发展至今的AI人工智能仍面临两大现实问题:
行业数据分散且收集困难,数据以孤岛的形式存在;隐私得不到保障,安全共享数据成为了一道壁垒。针对此,人们提出了一种名为「联邦学习」的隐私计算技术。
隐私计算AI网络PlatON宣布正式启动安全多方计算仪式Lumino:6月7号消息,隐私计算AI网络PlatON宣布正式启动安全多方计算仪式Lumino,参与者们能以分布式的方式参与PlatON生态网络。Lumino仪式分为两个计算组,针对底层不同的密码学配置,参与者可以选择加入其中一个,或者两个计算组都参加。计算过程将依次执行。一旦仪式启动,参与者运行开源的客户端软件,并在几个小时内完成计算,参与者可以在仪式开启后的任意时间加入。根据参与者设备和带宽的具体情况,此次计算通常需要1到10小时左右来运行客户端软件。另外,系统为每个参与者运行过程配置15小时的窗口,以鼓励参与者及时完成工作量。组织方将为每一位运行客户端软件的参与者采用一个可验证计算范式。[2021/6/7 23:18:18]
联邦学习,又名联邦机器学习、联合学习。它是AI人工智能的一门分支技术,旨在保障大数据交换时的信息安全、数据保护,在合法合规的前提下,有效帮助多行业的数据进行机器学习建模。
国内隐私计算技术联盟成立:4月19日,国内区块链隐私计算领域去中?化治理组织隐私计算技术联盟(PrivacyComputingInChina,简称“PCIC”)宣布成立。
PCIC9家创始成员机构为:OasisNetwork、Findora、Certik、MantaNetwork、Phala、CabinVC、Candaq、中国技术经济学会区块链分会、Blocklike。
PCIC旨在为隐私计算领域打造?个有公信?、开放、共赢的自治理组织。PCIC将通过轮值机制,由核?发起成员轮值管理隐私计算技术联盟社区,定期向市场传递隐私计算领域技术研讨及生态进展。[2021/4/19 20:35:47]

Phala Network宣布加入由Linux基金会、Facebook、微软等巨头组成的隐私计算联盟(CCC):据官方消息,Phala Network在博客宣布正式加入Linux基金会的隐私计算联盟(CCC,Confidential Computing Consortium),将与业内携手,共同解决跨行业数据传输加密和数据隐私保护问题。
“隐私计算联盟”(Confidential Computing Consortium)是由Linux基金会和多家巨头企业组建的联盟,致力于推进数据隐私并推广和制定可信执行环境(TEE)技术标准。该联盟其他成员公司包括Facebook、Google Cloud、微软、IBM、英特尔、Arm、AMD、英伟达等。[2020/11/10 12:14:06]
隐私保护是联邦学习最主要的关注点,在实际的应用中,联邦学习通过将数据的不同特征在加密的状态下加以聚合,以增强机器学习模型能力,再通过共享数据模型,避开原始数据共享,进而保证了数据的安全性。?
现场 | 王允臻:隐私计算是我到目前为止所了解到的唯一的真正保障数据主权的:在今日隐私计算发展研讨会的圆桌讨论中,万向控股CIO王允臻表示,分布式的逻辑,分布式逻辑就要求打通数据孤岛。前面有其他的演讲者也讲的很好,那么数据达不到有行政上的问题,组织关系上的问题,还有更重要的是一个隐私安全保护。就说我现在要让我的数据被利用,唯一的方法就是把数据开放。你要拿走我的数据,这样的话你是没有前途的,怎么来解决这个问题?我所谓的就是美国人说得data sovereignty,就是数据主权,假如说你没有办法保证你的数据,你是数据的唯一拥有者的话,谈得上什么主权,国家的土地主权不是说这块土地技术,国家又必须是一个排他性的唯一的,那么这样一来的话就可以和隐私计算就联系在一起,因为隐私计算是我到目前为止所了解到的唯一的真正保障数据主权的。[2019/9/17]
利用联邦学习的特点,即使是不导出企业数据的情况下,也能为三方或多方建立机器学习模型,既充分保护了数据隐私和数据安全,又为客户提供个性化、有针对性的服务,实现了互惠互利。?
同时,我们可以利用不同类别的联邦学习技术来解决数据异质性问题,突破传统AI技术的局限性。依照参与建模的数据源分布,联邦学习可分为横向联邦学习、纵向联邦学习和联邦迁移学习三类。?
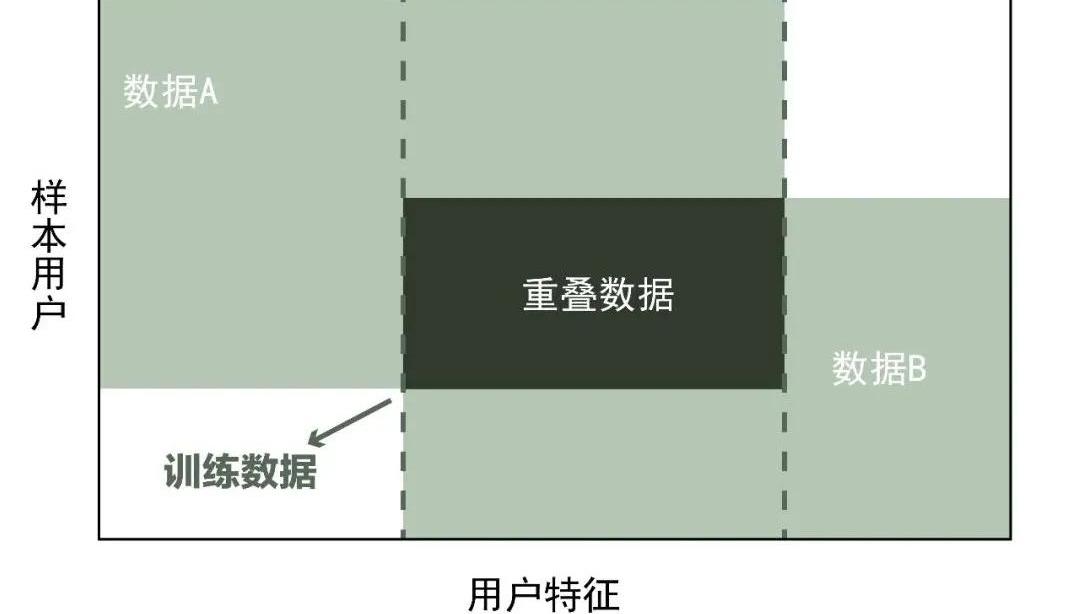
横向联邦学习假设收集两个数据集,这两个数据集用户特征重叠多,而用户重叠少。我们把数据集按照用户维度切分,取出双方用户特征相同,而用户不完全相同的部分数据作为机器的训练数据,这种模型称为横向联邦学习。?
例如,两个不同行政区的银行,用户群体分别来自所在行政区,重叠部分少。但是同作为银行,业务类似,因此数据集收集的用户特征则大体相同。因此,横向联邦学习模型收集的是两个数据集不完全相同的用户部分。?
如下图所示:?
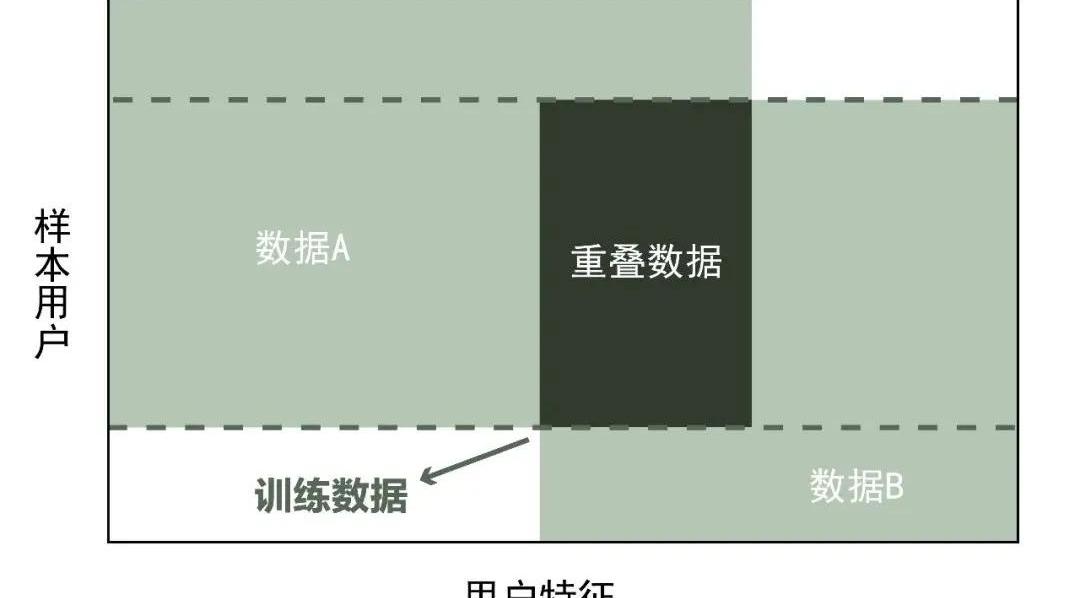
纵向联邦学习与横向联邦学习相反,在两个数据集用户重叠多、用户特征重叠少的情况下,纵向联邦学习把数据集按照数据特征维度切分,取出双方用户相同,而用户特征不完全相同的部分作为机器训练数据。?
例如,同一个行政区的银行和商超,其收集的数据用户群体大致类似,但银行和商超收集到的用户特征基本不同。因此,纵向联邦学习模型收集的是两个数据集不完全相同的用户特征部分。?
如下图所示:
联邦迁移学习在用于机器学习的数据集样本用户与用户特征重叠都较少的情况下,通常不对数据进行切分,而是引入联邦迁移学习,来解决数据不足的问题,从而提升模型的效果。
具体地,可以扩展已有的机器学习方法,使之具有横向联邦学习或者纵向联邦学习的能力。?例如,收集一家位于北京的银行和一家位于上海的商超的数据,由于受到地域限制,用户群体交集很小;同时,由于银行和商超类型的不同,二者收集的数据特征也基本无重合。?
引入联邦迁移学习,首先可以先让两个数据集训练各自的模型,之后通过加密模型数据,避免在传输中泄露隐私。之后,对这些模型进行联合训练,最后得出最优的模型,再返回给各个企业。?
如下图所示:?

多种类别的联邦学习方式使得机器学习模型更加具有通用性,可以在不同数据结构、不同行业间发挥作用,没有领域和算法限制,同时具有模型质量无损、保护隐私、确保数据安全的优势。?

在实际的应用中,类似销售、金融等行业,由于知识产权、隐私保护和数据安全等因素限制,数据壁垒很难打通。
联邦学习成为了解决这些问题的关键,在不影响数据隐私和安全的情况下,对来自多方的数据进行统一的建模,进行机器学习模型的训练,这些企业之间就能更好地进行数据协作。?
可以说,联邦学习为构建跨行业、跨地域的大数据和人工智能生态圈提供了良好的技术支持。?考虑到在整个训练过程中,进行模型更新的通信仍然可以向第三方或中央服务器显示敏感信息,因此联邦学习技术广泛地与安全多方计算、TEE或者区块链等技术结合应用,来增强联邦学习的隐私性和去信任。
但目前已有的方法通常以降低模型性能或系统效率为代价提供隐私,因此,如何在理论和经验上理解和平衡这些权衡,将是实现联邦学习技术广泛应用落地的一个相当大的挑战。
随着NFT爆发,过去12个月将载入史册。NFT自2014年以来一直存在,但它们的文化相关性在2021年得到巩固,几乎渗透到从艺术和音乐到慈善机构的每个行业,甚至出现在梅西百货的感恩节游行中.
据TechCrunch12月21日报道,总部位于洛杉矶的风投机构ChapterOne创始人兼管理合伙人JeffMorrisJr.表示.
近期,元宇宙概念成为资本、产业和科技界的讨论热点,核心在于提出了突破产业内卷的数字化解决方案。在打击挖矿、平台治理和双碳目标等强监管政策风向下,各地政府、各类学会和国内外大中小企业将元宇宙赋予未.
原标题:《波卡生态都有哪些流动性解决方案?》当行业焦点由过去的比特币扩容问题,转移到以太坊的扩容问题上来时,波卡生态仍在发生着积极的变化,Kusama和Polkadot的平行链已经开始稳健运行.
作者:Coinbase创始人&CEOBrianArmstrong以及Coinbase身份产品负责人AlexReeve最近一段时间,每个人都在谈论元宇宙.
原标题:《Sorare创始人:50%的Dapp将在ZK-Rollups上运行……NFT/游戏/体育2022预测》在Sorare,我们的论点一直是NFT可以将文化大众带到Web3.