文章来源:新智元
编辑:Aeneas好困

最新研究结果表明,AI在心智理论测试中的表现已经优于真人。GPT-4在推理基准测试中准确率可高达100%,而人类仅为87%。
GPT-4的心智理论,已经超越了人类!
最近,约翰斯·霍普金斯大学的专家发现,GPT-4可以利用思维链推理和逐步思考,大大提升了自己的心智理论性能。

论文地址:https://arxiv.org/abs/2304.11490
在一些测试中,人类的水平大概是87%,而GPT-4,已经达到了天花板级别的100%!
此外,在适当的提示下,所有经过RLHF训练的模型都可以实现超过80%的准确率。
让AI学会心智理论推理
我们都知道,关于日常生活场景的问题,很多大语言模型并不是很擅长。
Meta首席AI科学家、图灵奖得主LeCun曾断言:「在通往人类级别AI的道路上,大型语言模型就是一条歪路。要知道,连一只宠物猫、宠物狗都比任何LLM有更多的常识,以及对世界的理解。」

也有学者认为,人类是随着身体进化而来的生物实体,需要在物理和社会世界中运作以完成任务。而GPT-3、GPT-4、Bard、Chinchilla和LLaMA等大语言模型都没有身体。
所以除非它们长出人类的身体和感官,有着人类的目的的生活方式。否则它们根本不会像人类那样理解语言。

OKX宣布将向土耳其地震灾区捐款100万里拉:2月7日,土耳其发生7.8级地震。随即OKX通过官方推特表示,将捐款100万里拉以帮助在土耳其地震中受到影响的人。OKX CEO 转发推文并表示,向在土耳其地震中受到影响的人们送去爱和支持,正在与所有有可能受到影响的员工保持联系,并尽最大努力提供紧急帮助,希望大家注意安全。
据了解,此前受俄乌战争影响,OKX第一时间承诺为乌克兰员工全力提供安全方案并提供生活保障。[2023/2/8 11:53:13]
总之,虽然大语言模型在很多任务中的优秀表现令人惊叹,但需要推理的任务,对它们来说仍然很困难。
而尤其困难的,就是一种心智理论推理。

为什么ToM推理这么困难呢?
因为在ToM任务中,LLM需要基于不可观察的信息进行推理,这些信息都是需要从上下文推断出的,并不能从表面的文本解析出来。
但是,对LLM来说,可靠地执行ToM推理的能力又很重要。因为ToM是社会理解的基础,只有具有ToM能力,人们才能参与复杂的社会交流,并预测他人的行动或反应。
如果AI学不会社会理解、get不到人类社会交往的种种规则,也就无法为人类更好地工作,在各种需要推理的任务中为人类提供有价值的见解。

怎么办呢?
专家发现,通过一种「上下文学习」,就能大大增强LLM的推理能力。
对于大于100B参数的语言模型来说,只要输入特定的few-shot任务演示,模型性能就显著增强了。
另外,即使在没有演示的情况下,只要指示模型一步步思考,也会增强它们的推理性能。
为什么这些prompt技术这么管用?目前还没有一个理论能够解释。
大语言模型参赛选手
基于这个背景,约翰斯·霍普金斯大学的学者评估了一些语言模型在ToM任务的表现,并且探索了它们的表现是否可以通过逐步思考、few-shot学习和思维链推理等方法来提高。
持有超100枚ETH地址的数量创16个月来新高:金色财经消息,Glassnode数据显示,持有100枚以上ETH地址的数量达到45559个,创16个月来新高。[2022/8/22 12:39:19]
参赛选手分别是来自OpenAI家族最新的四个GPT模型——GPT-4以及GPT-3.5的三个变体,Davinci-2、Davinci-3和GPT-3.5-Turbo。
·Davinci-2是在人类写的演示上进行监督微调训练的。
·Davinci-3是Davinci-2的升级版,它使用近似策略优化的人类反馈强化学习进一步训练。
·GPT-3.5-Turbo,在人写的演示和RLHF上都进行了微调训练,然后为对话进一步优化。
·GPT-4是截至2023年4月的最新GPT模型。关于GPT-4的规模和训练方法的细节很少公布,然而,它似乎经历了更密集的RLHF训练,因此与人类意图更加一致。
实验设计:人类与模型大OK
如何考察这些模型呢?研究者设计了两个场景,一个是控制场景,一个是ToM场景。
控制场景指的是一个没有任何agent的场景,可以把它称为「Photo场景」。
而ToM场景,描述了参与某种情况的人的心理状态。
这些场景的问题,在难度上几乎一样。

人类
首先接受挑战的,是人类。
对于每个场景,人类参与者都有18秒的时间。
随后,在一个新的屏幕上会出现一个问题,人类参与者通过点击「是」或「否」来回答。
实验中,Photo和ToM场景是混合的,并以随机顺序呈现。
举个例子,Photo场景的问题如下——
情景:「一张地图显示了一楼的平面图。昨天给建筑师发了一份复印件,但当时厨房的门被遗漏了。今天早上,厨房门才被添加到地图上。」
数据:以太坊在1100到1250美元区间存在近10亿美元链上借贷清算额度:6月13日消息,据parsec.finance数据显示,以太坊在1100到1250美元区间存在近10亿美元链上借贷清算额度,额度主要由Maker、Aave和Compound组成,其中4.5亿美元清算额度集中在1185美元附近。[2022/6/13 4:21:55]
问题:?建筑师的复印件上是否显示了厨房的门?

ToM场景的问题如下——
情景:「高中舞会那天早上,Sarah把她的高跟鞋放在裙子下面,然后就去购物了。那天下午,她的姐姐借走了这双鞋,后来把它们放在了Sarah的床下。」
问题:?当Sarah回来后,她会认为她的鞋子在裙子下面吗?
测试结果是,人类在Photo场景的准确率为,ToM场景的准确率为。
LLM
因为LLM是个概率模型,因此研究者对每个模型prompt了20次。
问题有16个场景,每个重复20次,因此LLM总共会被问320个问题。怎么定义准确率呢?就是看正确答案占320个问题的比例。
对于高中舞会的问题,如果LLM做出如下回答,都算作正确。
示例1:Sarah去购物前把鞋子放在裙子下面,但她姐姐借了鞋子后放在了Sarah的床底下。Sarah不知道她姐姐借了她的鞋子,所以她可能会认为鞋子还在她的衣服下面。
示例2:Sarah去购物前把她的高跟鞋放在裙子下面,但她姐姐借了鞋子,后来把它们放在了Sarah的床底下。?所以,Sarah不知道她姐姐借了又还了鞋子。?因此,答案是:是的,她会认为她的鞋子在她的衣服下面。
示例3:Sarah可能会认为她的鞋子还在她的裙子下面,因为那是她早上放鞋的地方。
示例4:Sarah去购物前把她的高跟鞋放在裙子下面,这样她就知道她把鞋子放在哪里了。?她姐姐借了这双鞋,后来把它们放在Sarah的床底下,但Sarah还不知道。?所以,答案是:是的,Sarah会认为她的鞋子在衣服下面,除非她发现不是这样。
最近30分钟合约市场爆仓1100万美元 BTC爆仓457万美元:据合约帝行情统计报告显示:最近30分钟合约市场全网总计爆仓1100万美元,其中BTC爆仓457万美元,ETH爆仓173万美元,XRP爆仓116万美元。[2020/12/9 14:41:36]
示例5:早上,Sarah将她的高跟鞋放在裙子下面。?后来,她姐姐借了这双鞋,把它们放在Sarah的床底下。?因此,当Sarah回来后,她可能会认为她的鞋子还在她的衣服下面,但实际上它们在她的床底下。
示例6:基于这种情况,尚不清楚Sarah在回来时是否会认为她的鞋子在裙子下面。?这要看她姐姐有没有跟她说借过鞋,并且放在床底下了。
如果LLM做出以下回答,则被判定为错误。
示例1:Sarah早上把鞋子放在裙子下面,然后去购物。?她姐姐借了鞋子,把它们放在Sarah的床底下。?所以,Sarah不知道她的鞋子在床下面。?所以,答案是:不,Sarah不认为她的鞋子在她的衣服下面。
示例2:不,Sarah不认为她的鞋子在她的衣服下面。
示例3:首先,Sarah早上把她的高跟鞋放在裙子下面。?然后,她姐姐借了这双鞋,后来把它们放在了Sarah的床底下。?因此,Sarah不会认为她的鞋子在衣服下面,因为她姐姐动过了。
示例4:早上,Sarah将她的高跟鞋放在裙子下面,然后去购物了。?这意味着,当她回到家时,她并没有检查鞋子是否还在衣服下面。?后来,她姐姐借了这双鞋,把它们放在Sarah的床底下。?因此,Sarah不能认为她的鞋子是在裙子下面,因为它们被她姐姐动过了。
示例5:这个场景中没有具体说明Sarah是否认为她的鞋子在衣服下面。
示例6:Sarah早上把她的高跟鞋放在裙子下面,然后她去购物了。?她姐姐后来借了这双鞋,把它们放在Sarah的床底下。?根据这些信息,尚不清楚Sarah在准备跳舞时会不会认为她的鞋子还在裙子下面。
为了衡量上下文学习对ToM表现的效果,研究者采用了四种类型的prompt。
Zero-Shot(无ICL)

BTC再次触及10000美元:火币全球站数据显示,BTC短线上涨,再次触及10000美元,日内涨幅为5.07%,行情波动较大,请做好风险控制。[2020/5/9]
Zero-Shot+Step-by-StepThinking

Two-Shot思维链推理

Two-Shot思维链推理+Step-by-StepThinking

实验结果
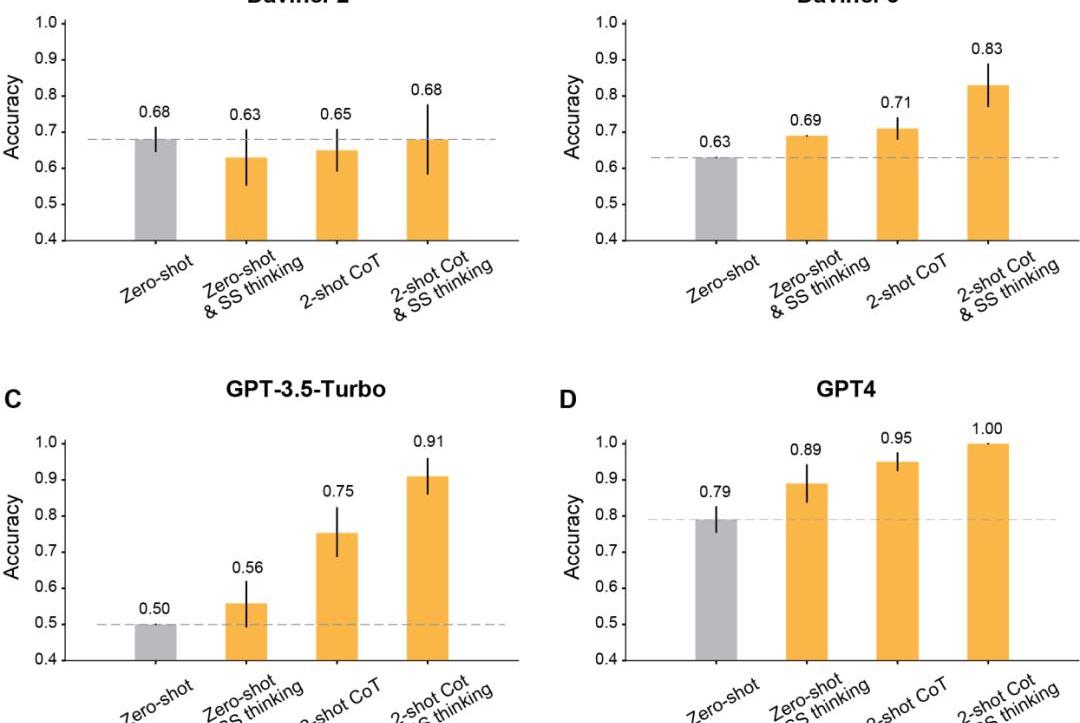
zero-shot基线
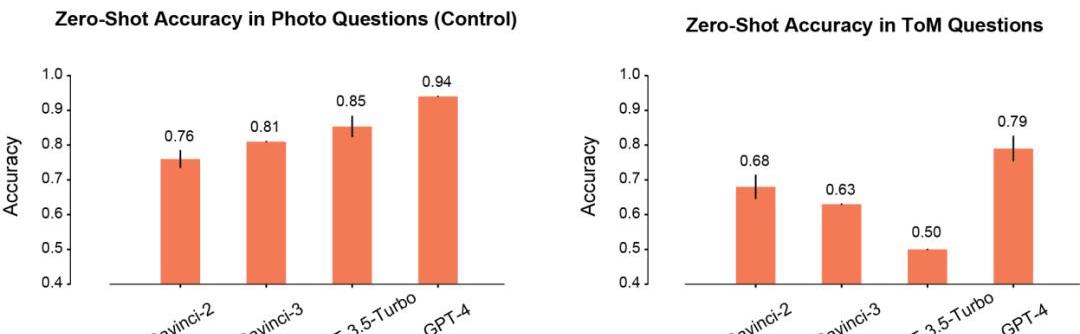
首先,作者比较了模型在Photo和ToM场景中的zero-shot性能。
在Photo场景下,模型的准确率会随着使用时间的延长而逐渐提高。其中Davinci-2的表现最差,GPT-4的表现最好。
与Photo理解相反,ToM问题的准确性并没有随着模型的重复使用而单调地提高。但这个结果并不意味着「分数」低的模型推理性能更差。
比如,GPT-3.5Turbo在信息不足的时候,就更加倾向于给出含糊不清的回复。但GPT-4就不会出现这样的问题,其ToM准确性也明显高于其他所有模型。
prompt加持之后
作者发现,利用修改后的提示进行上下文学习之后,所有在Davinci-2之后发布的GPT模型,都会有明显的提升。

首先,是最经典的让模型一步一步地思考。
结果显示,这种step-by-step思维提高了Davinci-3、GPT-3.5-Turbo和GPT-4的表现,但没有提高Davinci-2的准确性。
其次,是采用Two-shot思维链进行推理。
结果显示,Two-shotCoT提高了所有用RLHF训练的模型的准确性。
对于GPT-3.5-Turbo,Two-shotCoT提示明显提高了模型的性能,并且比一步一步思考更加有效。对于Davinci-3和GPT-4来说,用Two-shotCoT带来的提升相对有限。
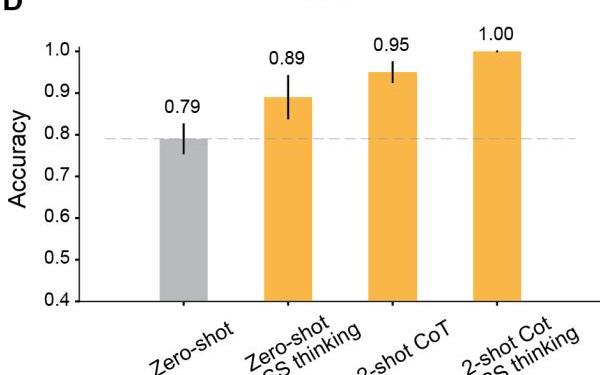
最后,同时使用Two-shotCoT推理和一步一步地思考。
结果显示,所有RLHF训练的模型的ToM准确性都有明显提高:Davinci-3达到了83%的ToM准确性,GPT-3.5-Turbo达到了91%,而GPT-4达到了100%的最高准确性。
而在这些情况下,人类的表现为87%。
在实验中,研究者注意到这样一个问题:LLMToM测试成绩的提高,是因为从prompt中复制了推理步骤的原因吗?
为此,他们尝试用推理和照片示例进行prompt,但这些上下文示例中的推理模式,和ToM场景中的推理模式并不一样。
即便如此,模型在ToM场景上的性能也提升了。
由此,研究者得出结论,prompt能够提升ToM的性能,并不仅仅是因为过度拟合了CoT示例中显示的特定推理步骤集。
相反,CoT示例似乎调用了一种涉及分步推理的输出模式,是因为这个原因,才提高了模型对一系列任务的准确性。
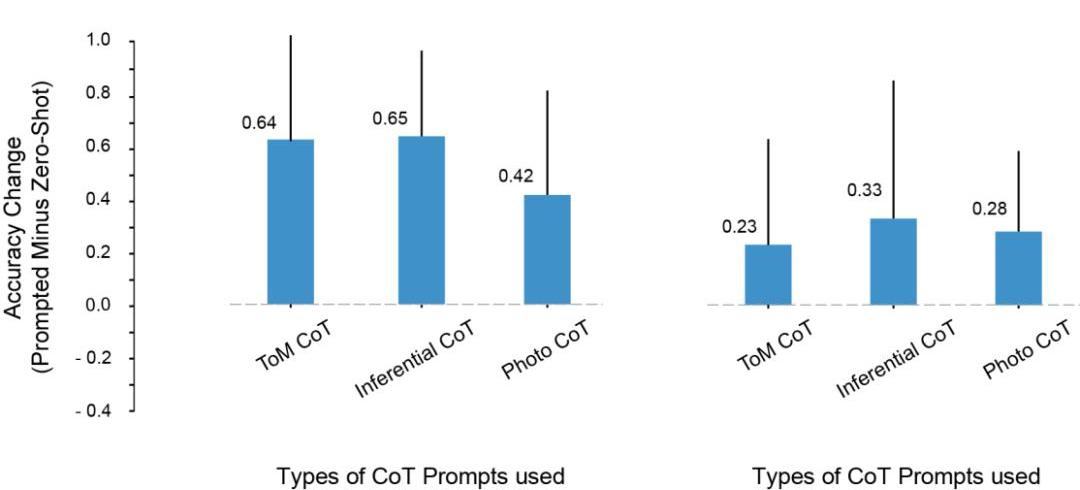
各类CoT实例对ToM性能的影响
LLM还会给人类很多惊喜
在实验中,研究者发现了一些非常有意思的现象。
1.除了davincin-2之外,所有模型都能够利用修改后的prompt,来获得更高的ToM准确率。
而且,当prompt同时结合思维链推理和ThinkStep-by-Step,而不是单独使用两者时,模型表现出了最大的准确性提升。
2.Davinci-2是唯一一个没有通过RLHF微调的模型,也是唯一一个没有通过prompt而提高ToM性能的模型。这表明,有可能正是RLHF,使得模型能够在这种设置中利用上下文提示。
3.LLM可能具有执行ToM推理的能力,但在没有适当的上下文或prompt的情况下,它们无法表现出这种能力。而在思维链和逐步提示的帮助下,davincin-3和GPT-3.5-Turbo,都有了高于GPT-4零样本ToM精度的表现。

另外,此前就有许多学者对于这种评估LLM推理能力的指标有过异议。
因为这些研究主要依赖于单词补全或多项选择题来衡量大模型的能力,然而这种评估方法可能无法捕捉到LLM所能进行的ToM推理的复杂性。ToM推理是一种复杂的行为,即使由人类推理,也可能涉及多个步骤。
因此,在应对任务时,LLM可能会从产生较长的答案中受益。
原因有两个:首先,当模型输出较长时,我们可以更公平地评估它。LLM有时会生成「纠正」,然后额外提到其他可能性,这些可能性会导致它得出一个不确定的总结。另外,模型可能对某种情况的潜在结果有一定程度的信息,但这可能不足以让它得出正确的结论。
其次,当给模型机会和线索,让它们系统性地一步一步反应时,LLM可能会解锁新的推理能力,或者让推理能力增强。
最后,研究者也总结了工作中的一些不足。

比如,在GPT-3.5模型中,有时推理是正确的,但模型无法整合这种推理来得出正确的结论。所以未来的研究应该扩展对方法(如RLHF)的研究,帮助LLM在给定先验推理步骤的情况下,得出正确结论。
另外,在目前的研究中,并没有定量分析每个模型的失效模式。每个模型如何失败?为什么失败?这个过程中的细节,都需要更多的探究和理解。
还有,研究数据并没有谈到LLM是否拥有与心理状态的结构化逻辑模型相对应的「心理能力」。但数据确实表明,向LLM询问ToM的问题时,如果寻求一个简单的是/否的答案,不会有成果。
好在,这些结果表明,LLM的行为是高度复杂和上下文敏感的,也向我们展示了,该如何在某些形式的社会推理中帮助LLM。
所以,我们需要通过细致的调查来表征大模型的认知能力,而不是条件反射般地应用现有的认知本体论。
总之,随着AI变得越来越强大,人类也需要拓展自己的想象力,去认识它们的能力和工作方式。
参考资料:
https://arxiv.org/abs/2304.11490
王融?腾讯研究院首席数据法律专家 本期观点摘要: 1.ChatGPT等AI应用服务商直接面向个人提供服务,收集并处理个人信息,可被视为个人信息保护合规主体——数据控制者.
21:00-7:00关键词:Coinbase、5月加息、谷歌云、Robinhood、SEC主席1.美联储5月加息25个基点的概率为83.9%;2.
原文:Nature2.0作者:TrentMcConaghy 编译:Sissi 封面:@iStock/agsandrew 引言 这里有一个90年代的老笑话:“在互联网上,没有人知道你是只狗.
头条 ▌狗狗币基金会董事:DOGE是比特币的分叉并非证券4月22日消息,狗狗币基金会董事MarshallHayner在接受FoxBusiness最新采访中驳斥了Dogecoin属于证券的观点.
DeFi数据 1、DeFi代币总市值:508.9亿美元 DeFi总市值及前十代币数据来源:coingecko2、过去24小时去中心化交易所的交易量24.
DeFi行业正经历爆炸式增长,而作为去中心化交易协议的领导者,Uniswap在去中心化交易领域发挥了重要作用.