演讲分成四个部分,第一部分张烨介绍了开发背景以及我们为什么首先需要zkEVM以及为什么它在最近两年间变得如此受欢迎,第二部分通过一个完整的流程,讲解如何从头开始构建zkEVM包括算术化和证明系统,第三部分通过一些有趣的研究问题来谈论了Scroll在构建zkEVM时遇到的问题,最后介绍了一些其他使用zkEVM的应用。


背景和动机
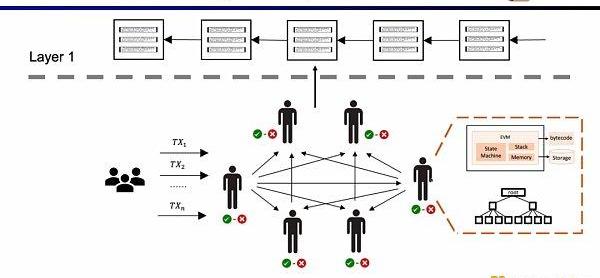
传统的Layer1区块链会有一些节点通过P2P网络共同维护。他们在收到用户的交易时,会在EVM的虚拟机内执行,读取调用合约和存储,并依照交易更新全局的状态树。
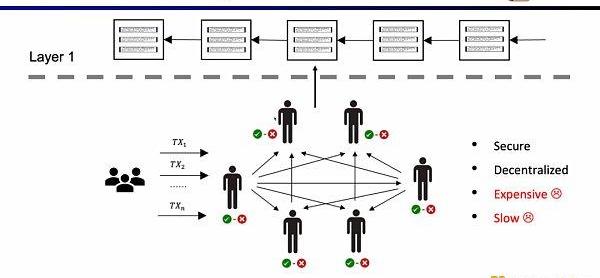
这样的架构的优势在于去中心化和安全性,缺陷就是在L1上的交易手续费昂贵,并且交易确认缓慢。
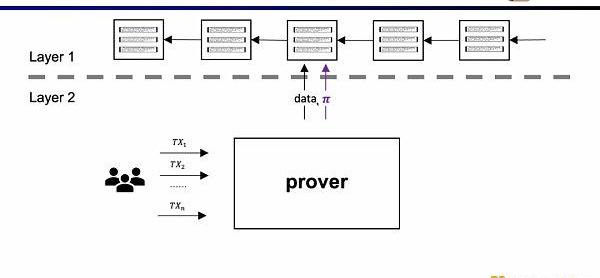
ZK-Rollup的架构中,L2网络只需将数据和验证数据正确性的证明上传至L1,其中证明通过零知识证明电路计算而来。
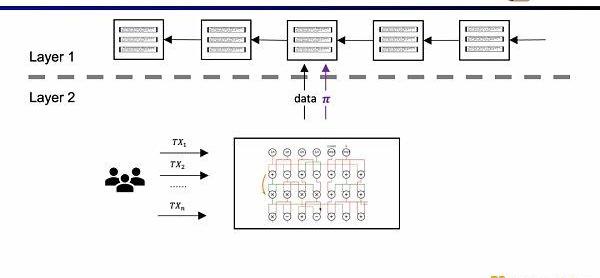
在早期的ZK-Rollup中,电路是针对特定应用而设计,用户需要将交易发送给不同的证明者,然后不同应用的ZK-Rollup再将自己的数据和证明提交至L1。这样带来的问题是,丧失了原先L1合约的可组合性。
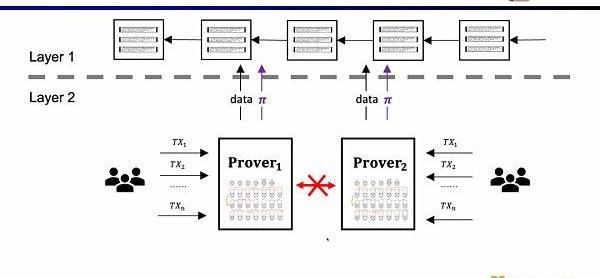
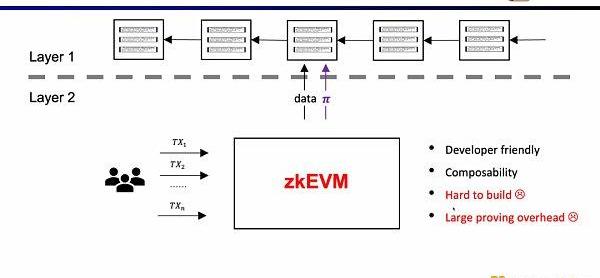
Scroll所要做的是原生的zkEVM方案,是一种通用型的ZK-Rollup。这样不仅对用户而言更友好,对于开发者而言也可以获得在L1上的开发体验。当然这背后的开发难度非常之大,并且现在的证明生成的代价也非常高。
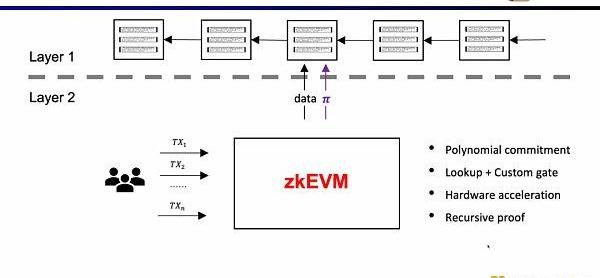
幸运的是,零知识证明的效率在过去两年里已经大幅提高了,这也是为什么在最近两年zkEVM变得如此受欢迎。至少有四个原因让它变得可行,第一是多项式承诺的出现,在原先Groth16证明系统下,约束的规模非常之庞大,而多项式承诺可以支持更高阶的约束,缩小证明规模;第二是查找表和自定义门的出现,可以支持更灵活的设计,使证明更加高效;第三是硬件加速方面的突破,通过GPU,FPGA和ASIC可以将证明时间缩短1-2个数量级,第四是在递归证明下,可以将多个证明压缩成一个证明,使得证明变得更小更易于验证。所以结合这四个因素,零知识证明的生成效率要比两年前高出三个数量级,这也是Scoll的起源。
Scroll基金会与Chainlink Labs达成合作关系:金色财经报道,基于zkEVM的zkRollupScroll基金会宣布正在与 Chainlink Labs 合作,为 Scroll 的开发人员提供 Chainlink Web3 服务。Scroll 已加入Chainlink SCALE (第 1 层和第 2 层启用的可持续 Chainlink 访问)计划,以帮助促进其以太坊原生zkEVM扩展解决方案的采用。[2023/8/23 18:16:18]
根据JustinDrake的定义,zkEVM可以分为三类,第一类是语言级别的兼容,主要原因是EVM不是为ZK而设计,有很多对ZK不友好的操作码,因此会造成大量的额外开销。因此像Starkware和zkSync选择在语言层面将Solidity或者Yul编译到ZK友好的编译器中。
第二类是Scroll在做的字节码层面的兼容,是直接证明EVM的字节码处理正确与否,直接继承了以太坊的执行环境。在这里可做的一些取舍是,使用和EVM不一样的状态根,例如使用ZK友好的数据结构。Hermez和Consensys也在做类似的事情。
第三类是共识层面的兼容,这里的取舍在于不仅需要保持EVM不变,还包括储存结构等实现以太坊完全兼容,代价是需要更长的证明时间。而Scroll正在和以太坊基金会的PSE团队合作构建,来实现以太坊的ZK化

从0到1构建zkEVM

第二部分,张烨向大家展示了如何从零开始建立ZKVM。
完整流程
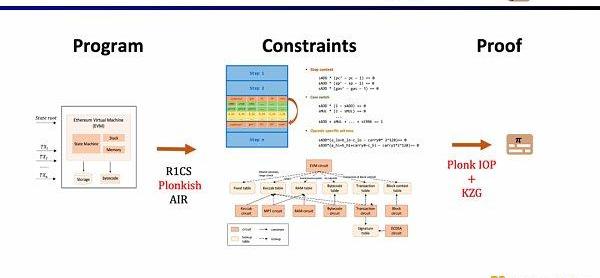
首先,在ZKP的前端部分,你需要通过数学的算术化来表示你的计算,最常用的就是线性的R1CS,以及Plonkish和AIR。通过算术化得到约束后,在ZKP的后端你需要运行证明算法,来证明计算正确性,这里列举了最常用的多项式交互式谕示证明(PolynomialIOP)和多项式承诺方案(PCS)。
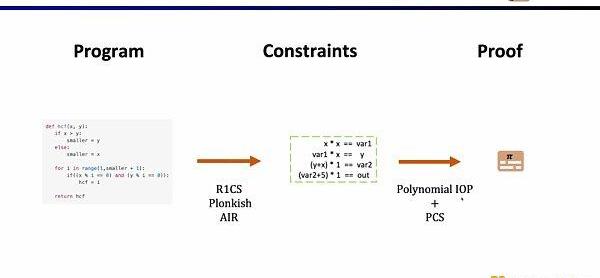
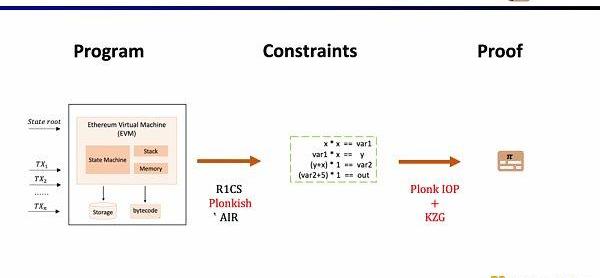
在这里我们需要证明zkEVM,Scroll使用的是Plonkish,PlonkIOP,以及KZG的组合。
为了理解我们为什么使用这三者的方案。我们首先从最简单的R1CS开始,R1CS中的约束,是线性组合乘以线性组合等于线性结合。你可以加上任何变量的线性组合而没有额外的开销,但是在每个约束中阶数最大是2。因此对于阶数较高的运算,需要的约束就越多。
DEX聚合器OpenOcean集成Scroll Alpha测试网:金色财经报道,DEX聚合器OpenOcean宣布集成Scroll Alpha测试网,Scroll是以太坊主网的新原生zkEVM扩展解决方案。[2023/8/17 18:04:14]

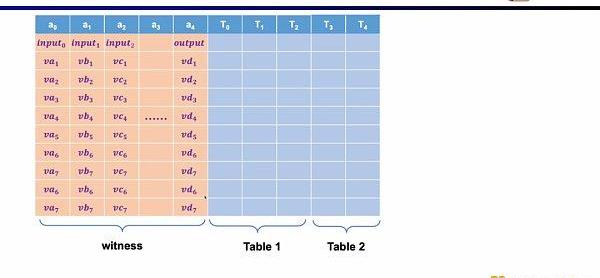
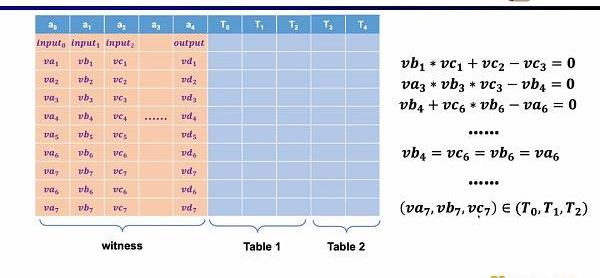
而在Plonkish中,你需要将所有的变量填入表格,包括输入,输出以及中间变量的见证。在此之上,你可以定义不同的约束。在Plonkish中有三种类型的约束可以使用。
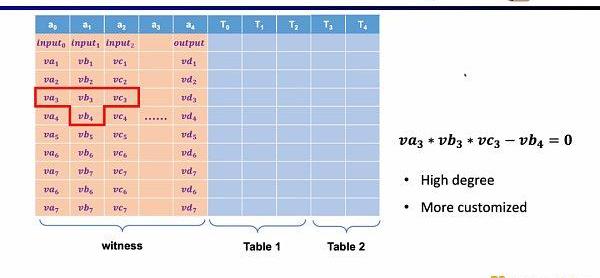
第一种约束是自定义门,你可以定义不同单元格之间的多项式约束关系,例如va3*vb3*vc3-vb4=0。相比R1CS来说,阶数可以更高,因为你可以定义任何一个变量的约束,并且可以定义一些非常不一样的约束。
第二种约束是Permuation,即等价性校验(equalitychecks)。可以用来检查不同单元格的等价性,常用于关联电路中的不同门,比如证明上一个门的输出等于下一个门的输入。
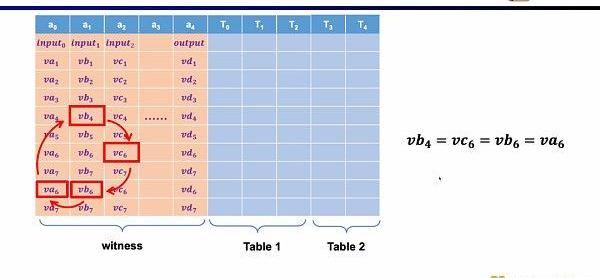
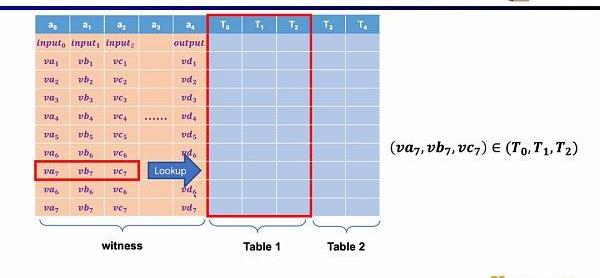
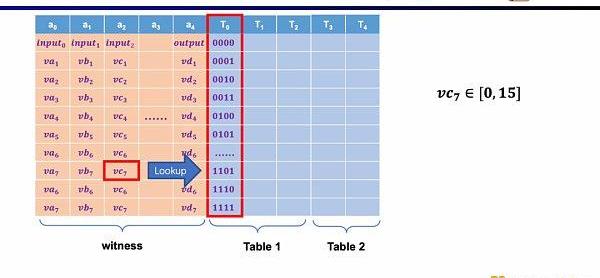
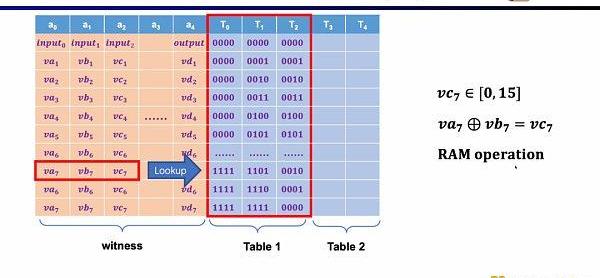
最后一种约束是查找表(LookupTable)。我们可以将查找表理解成变量之间存在一个关系,该关系可以表示成一个表。例如我们想要证明vc7在0-15范围内,在R1CS中你首先需要把这个数值分解为4位二进制,然后证明每位在0-1的范围内,这将需要四个约束。而在Plonkish中,你可以将所有可能的范围列在同一列,只需要证明vc7属于该列即可,这对范围证明非常高效,在zkEVM中,查找表对于证明内存读写非常有用。
小结一下,Plonkish同时支持自定义门,等价性校验和查找表,可以非常灵活的满足不同的电路需要。简单对比下STARK,STARK中每一行是一个约束,约束需要表示行与行之间的状态转换,但Plonkish中的自定义约束灵活性显然更高。
BitsCrunch激励测试网已启动,主网预计于2023年9月推出:金色财经报道,由人工智能驱动的去中心化NFT数据网络bitsCrunch Network激励测试网已上线并向公众开放。主网预计于2023年9月推出。BitsCrunch已为其测试网计划的第一轮指定了4,600,000BCUT代币(相当于代币供应总量的0.46%)。已专门为任务3分配了1,500,000个代币。[2023/8/4 16:19:04]
现在的问题是在zkEVM中,我们如何选择前端。对于zkEVM主要有四个挑战。第一个挑战是EVM的字段是256位,这意味着需要高效得对变量进行范围约束;第二个挑战是EVM有很多ZK不友好的操作码,因此需要非常大规模的约束来证明这些操作码,例如Keccak-256;第三个挑战是内存读写问题,你需要一些有效的映射来证明你所读取的和之前所写入的是一致的;第四个挑战是EVM的执行踪迹是动态变化的,因此我们需要自定义门来适配不同的执行踪迹。出于上述的考虑,我们选择了Plonkish。
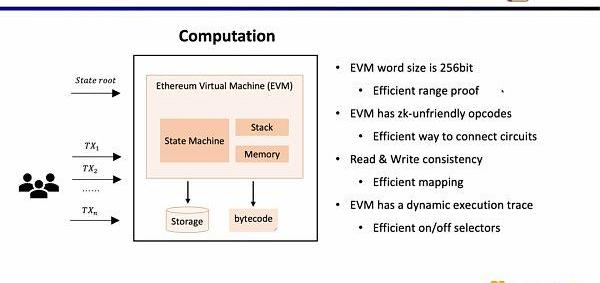
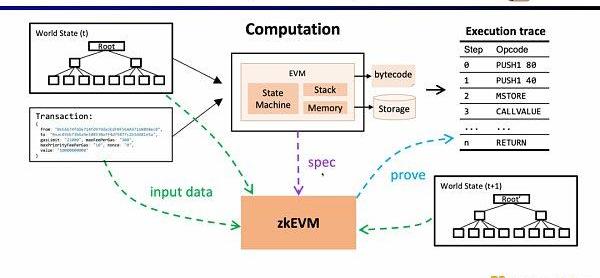
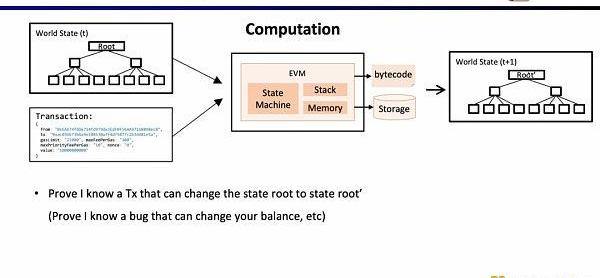
接下来,我们看zkEVM的完整流程,基于初始的全局状态树,一笔新的交易进来后,EVM会读取存储和调用的合约的字节码,根据交易生成相应的执行踪迹例如PUSH,PUSH,STORE,CALLVALUE,然后逐步执行更新全局状态,得到交易后的全局状态树。而zkEVM是将初始的全局状态树,交易本身,以及交易后的全局状态树作为输入,根据EVM的规范,来证明执行踪迹的执行正确性。
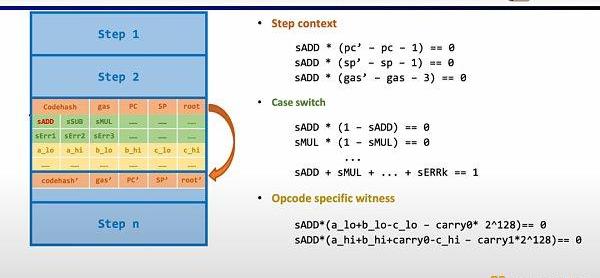
深入EVM电路细节,每一步执行踪迹都有对应的电路约束。具体来说,每一步的电路约束包含StepContext,CaseSwitch,OpcodeSpecificWitness。StepContext包含执行踪迹对应的codehash,剩余gas和计数器;CaseSwitch包含所有的操作码,所有的错误情况,以及该步的相应操作;OpcodeSpecificWitness包含了操作码所需的额外见证,例如运算数等。

以简单的加法为例,需要确保加法的操作码的控制变量sADD设置为1,其他操作码控制变量均为零。在StepContext中,通过设置gas'-gas-3=0来约束消耗的gas等于3,同理约束计数器,栈指针在该步后累加1;在CaseSwitch中,通过操作码控制变量和为1来约束该步为加法操作;在OpcodeSpecificWitness中,对运算数的实际加法进行约束。
Scroll联创:预计年内上线主网,一直看重开发、社区等高质量互动:5月22日消息,以太坊Layer2解决方案Scroll联合创始人Sandy Peng在接受区块先生Mr Block采访时表示,我们很有信心会在未来几个月以内推出我们的主网,具体的时间还没有定,应该是在Q3、Q4。
此外,Sandy就Token相关问题表示,我们会花很多的时间写教育类blog,帮助大家了解我们的技术、原理和概念。现在会花很多的时间精力去鼓励builder(开发者)去做一些能让大家共用、有用的东西,同时还会鼓励社区成员加强学习活动以投资自己,长期来看,肯定会有特别大的(知识上的)收益。还是要做一些building(开发)类的利他活动,与building、organization(社区)有关的,虽然很难衡量但却是我们一直看重的。更高质量的互动方式第一就肯定是自我的提升和学习。第二就是在Scroll上做一些高质量的创业。[2023/5/22 15:18:59]
此外还需要额外的电路约束,来保证运算数从内存读取的正确性。这里我们首先需要构建一个查找表来证明运算数属于内存。并通过内存电路(RAMCircuit)来验证内存表的正确性。
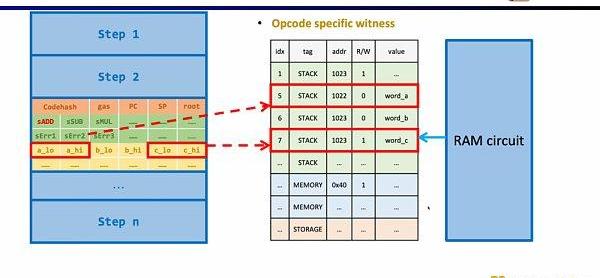
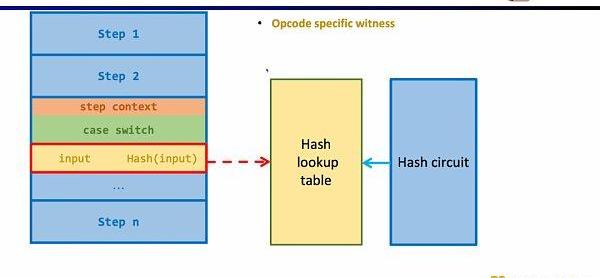
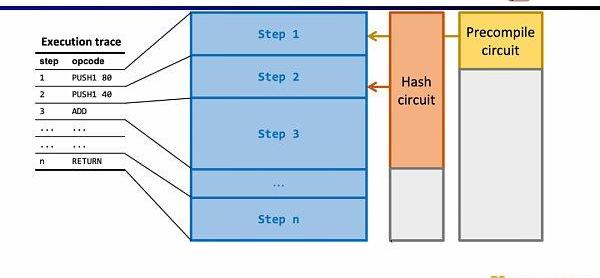
同样的方法可以适用于zk不友好的哈希函数,构建哈希函数的查找表,将执行踪迹中的哈希输入和输出映射到查找表,利用额外的哈希电路(HashCircuit)来验证哈希查找表的正确性。
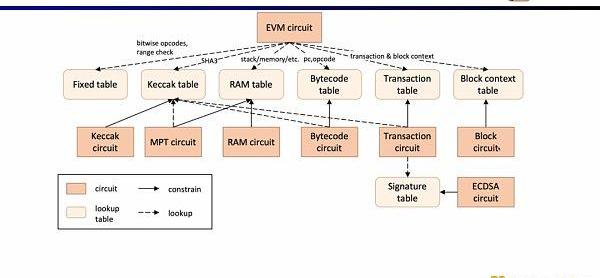
现在我们来看zkEVM的电路架构,核心的EVM电路用于约束执行踪迹每一步的正确性,在一些EVM电路约束难度较大的地方,我们通过查找表来映射,包括FixedTable,KeccakTable,RAMTable,Bytecode,Transaction,BlockContext,然后利用单独的电路来约束这些查找表,例如Keccak电路用于约束Keccak表。
小结一下,zkEVM的完整工作流如下图所示。
证明系统
因为在L1上直接验证上述的EVM电路,内存电路,存储电路等,开销巨大,Scroll的证明系统采用了两层架构。
第一层负责直接证明EVM本身,需要大量的计算来生成证明。因此第一层证明系统要求支持自定义门和查找表,对硬件加速友好,在低峰值内存下并行生成计算,且验证电路规模小,可以快速验证。有前景的可选方案包括Plonky2,Starky,eSTARK,它们前端基本上都使用Plonk,但后端可能使用了FRI,并且都满足上述的四个特性。另一类可选的方案包括Zcash所开发的Halo2,以及KZG版本的Halo2。
Ripple Escrow钱包解锁10亿枚XRP:1月1日消息,据Whale Alert数据,两笔分别为5亿枚XRP从Ripple Escrow钱包中解锁。[2022/1/1 8:18:01]
还有一些新的证明系统也有很有前景,例如最近移除了FFT的HyperPlonk,而NOVA证明系统可以做到更小的递归证明。但它们在研究中只支持R1CS,如果他们未来可以支持Plonkish并且应用于实践,将非常实用高效。
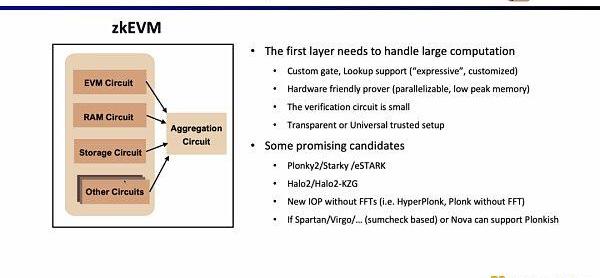
第二层证明系统用于证明第一层证明的正确性,需要可以在EVM中高效进行验证,理想情况下,最好也是硬件加速友好并且支持transparent或者universalsetup。有前景的可选方案包括Groth16和列数较少的Plonkish证明系统。Groth16仍然是目前研究中证明效率极高的代表,而Plonkish证明系统在列数较少的情况下,也可以达到较高的证明效率。
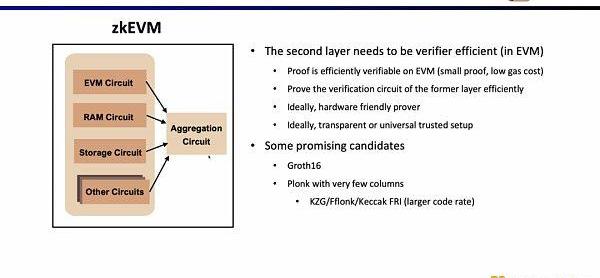
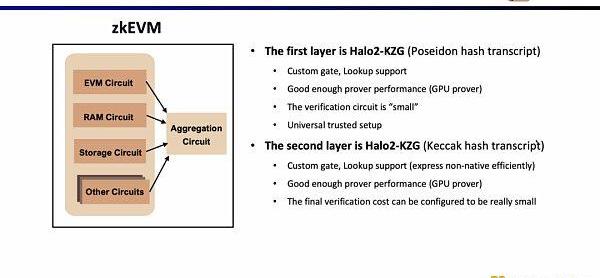
在Scroll,我们在两层证明系统中我们都采用了Halo2-KZG证明系统。因为Halo2-KZG可以支持自定义门和查找表,在GPU硬件加速下性能良好,且验证电路规模小,可以快速验证。区别在于我们在第一层证明系统中我们使用了Poseidon哈希,进一步提高证明效率,而第二层证明系统因为直接在以太坊上验证,仍然使用了Keccak哈希。Scroll也在探索多层证明系统的可能性,来进一步聚合第二层证明系统生成的聚合证明。
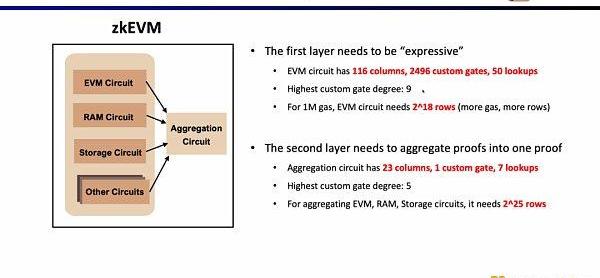
当前实现下,Scroll的第一层证明系统EVM电路有116列,2496个自定义门,50个查找表,最高阶数为9,1MGas下需要2^18行;而第二层证明系统的聚合电路仅有23列,1个自定义门,7个查找表,最高阶数为5,为了聚合EVM电路,内存电路,存储电路,需要2^25行。
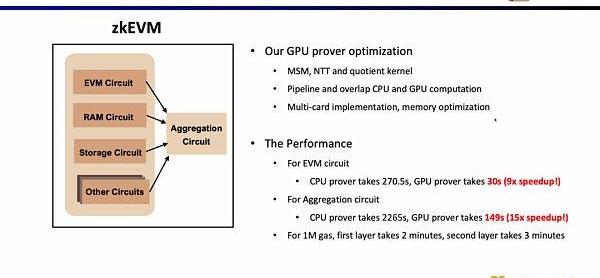
Scroll在GPU硬件加速方面也做了非常多的研究和优化工作,对于EVM电路,优化后的GPU证明者仅需30s,相较CPU证明者提升了9倍的效率;而对于聚合电路,优化后的GPU证明者仅需149s,相较CPU提升了15倍的效率。在当前的优化条件下,1MGas第一层证明系统大约需要2分钟,第二层证明系统大约需要3分钟。
有趣的研究问题

第三部分,张烨谈论了一些Scroll在构建zkEVM过程中有趣的研究问题,从前端的算术化电路到证明者的实现。
电路
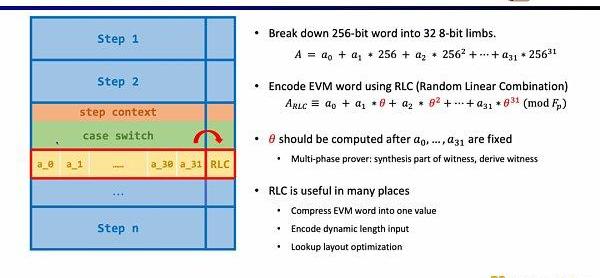
首先是电路中的随机性,因为EVM字段是256位,我们需要将其拆分成32个8位的字段,从而更高效得进行范围证明。随后我们使用随机线性组合(RandomLinearCombination,RLC)的方法,利用随机数将32个字段编码成1个,只需要验证该字段就可以验证原始的256位字段。但是问题在于随机数的生成需要在拆分字段之后,才能确保不被篡改。因此Scroll和PSE团队提出了多阶段证明者的方案,来确保在字段拆分之后,再利用随机数生成RLC,该方案被封装在了ChallengeAPI中。RLC在zkEVM中有许多应用场景,不仅可以压缩EVM字段成一个字段,也可以加密不定长的输入,或是优化查找表的布局,但仍然有许多开放性的问题需要解决。
电路方面第二个有趣的研究问题是电路布局。Scroll前端之所以采用Plonkish,是因为EVM的执行踪迹是动态变化的,需要能支持不同的约束,变化的等价性检验,而R1CS的标准化门需要更大的电路规模来实现。但Scroll目前使用了2000多个自定义门来满足动态变化的执行踪迹,也在探索如何进一步优化电路布局,包括将Opcode拆分成MicroOpcode,或是复用相同表格内的单元格。
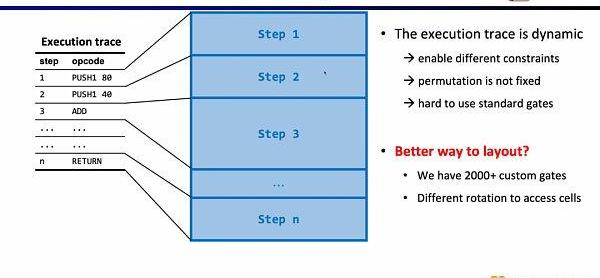
电路方面第三个有趣的研究问题是动态规模。因为不同的操作码的电路规模不同,但为了满足动态变化的执行踪迹,每一步的操作码都需要满足最大的电路规模,例如Keccak哈希,因此我们实际上付出了额外的开销。假设我们可以使zkEVM动态适应动态变化的执行踪迹,这将节省不必要的开销。
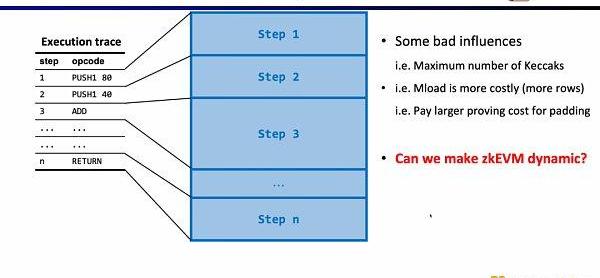
证明者
在证明者方面,Scroll在GPU加速上已经对MSM和NTT进行了大量的优化,但现在的瓶颈转移到了见证生成和复制数据这块。因为假设MSM和NTT占据了80%的证明时间,即使硬件加速可以将这部分效率提升若干个数量级,但原先见证生成和复制数据20%的证明时间将变成新的瓶颈所在。证明者的另一个问题是需要大量的内存,因此也需要探索更便宜更去中心化的硬件方案。

同时Scroll也在探索硬件加速和证明算法方面,来提升证明者的效率。目前主要有两个大方向,或是切换至更小的域,例如使用64位的Goldilocks域,32位的梅森数等,或是坚持基于椭圆曲线的新证明系统,例如SuperNova。当然也有其他的一些别的可能路径,欢迎有想法的朋友直接联系Scroll。

安全性
在构建zkEVM时,安全性是至关重要的。PSE和Scroll共同构建的zkEVM有大约3万4千行代码,从软件工程角度,这些复杂的代码库在很长一段时间内是不可能没有漏洞的。Scroll目前在通过大量的审计,包括业内最顶尖的审计公司,来审核zkEVM的代码库。


其他使用zkEVM的应用

第四部分探讨了其他一些使用了zkEVM的应用。
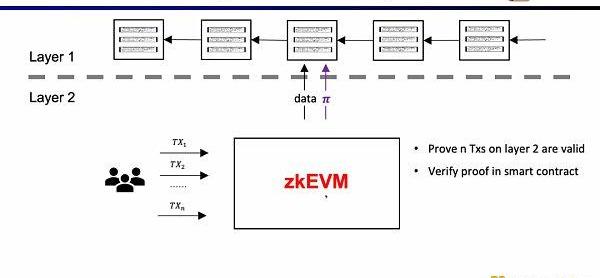
在zkRollup的架构中,我们通过在L1的智能合约,来验证在L2上的n笔交易是有效的。
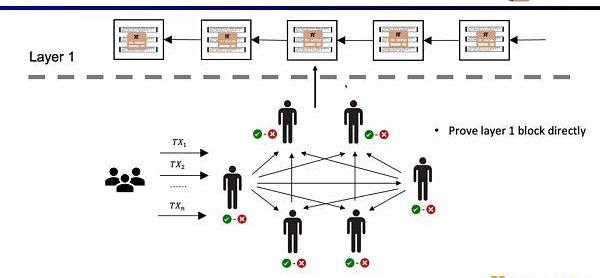
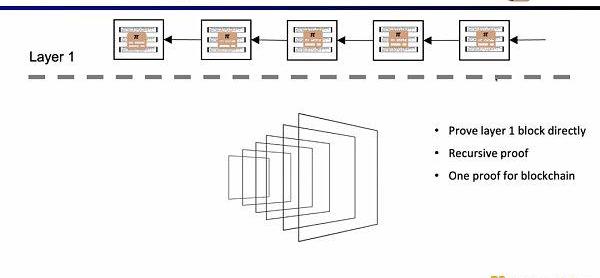
如果我们直接验证L1的区块,那么L1的节点就不需要重复执行交易,只需要验证每一个区块证明的有效性。这样的架构方案称为EnshrineBlockchain。目前在以太坊上直接实现难度非常之大,因为需要验证整个以太坊区块,其中会包括验证大量签名,随之带来更长的证明时间和更低的安全性。当然也已经有一些其他公链在通过递归证明,使用单个证明,来验证整个区块链,例如Mina。
因为zkEVM可以证明状态转换,它也可以被白帽所利用,来证明自己知道某些智能合约的漏洞,寻求项目方的赏金。
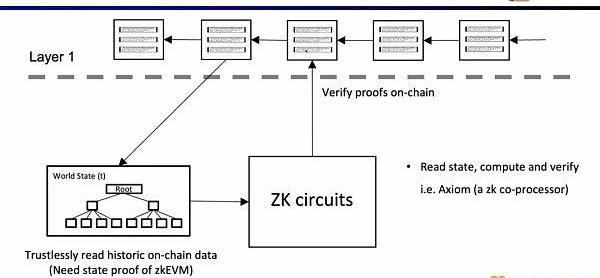
最后一个用例是,是通过零知识证明来证明对历史数据的声明,作为预言机来使用,目前Axiom正在做这方面的产品。最近的ETHBeijing黑客松上,GasLockR团队正是利用了这一特性,证明了历史的Gas开销。
最后,Scroll正在构建zkRollup的以太坊通用扩容解决方案,使用了非常先进的算术化电路和证明系统,并且通过硬件加速构建快速的验证器,证明递归。目前Alpha测试网已经上线,并稳定运行了很长时间。
当然仍然有一些有趣的问题需要解决,包括协议设计和机制设计,零知识工程和实际效率,欢迎大家加入Scroll一起构建!

来源:panewslab
原文:YeZhang
编译:F.F
标签:PLOCODECCANLINKXplosive Ethereumcode币的发行价CCARtronlink钱包如何导入资产
原文标题:EthereumAllCoreDevelopersConsensusCall#107Writeup原文作者:ChristineKim2023年4月20日,以太坊开发者齐聚一堂.
金色财经报道,以太坊联合创始人VitalikButerin在Zuzalu核心开发演示期间宣布ETH3.0路线图。以太坊3.0路线图承诺对网络进行重大升级和更改,包括引入权益证明共识机制、分片等.
金色财经报道,美国财政部助理部长ElizabethRosenberg表示,财政部正在加强其监管制度,DeFi应该在一些合规方面进行规划.
作者|大圣Web3 2023年3月23日,Arbitrum官网开启ARB申领,一大批用户直接赢麻了.
原文:EthereumAllCoreDevelopersConsensusCall#107Writeup作者:ChristineKim 2023年4月20日,以太坊开发者齐聚一堂.
金色财经报道,4月27日,香港金融管理局副总裁阮国恒发布文章《迎接机遇?应对开户》表示,近月我们积极与银行讨论,亦表明没有任何法律或监管要求禁止在香港经营的银行向虚拟资产相关机构提供银行服务.