当与区块链数据集一起使用时,机器学习模型往往会过拟合。什么是过度拟合以及如何解决?
乍一看,使用机器学习来分析区块链数据集的想法听起来非常吸引人,但这是充满挑战的道路。在这些挑战中,当将机器学习方法应用于区块链数据集时,缺少标记数据集仍然是要克服的最大难题。这些局限性导致许多机器学习模型使用非常小的数据样本进行操作,以训练和过度优化那些引起过拟合现象的模型。今天,我想深入探讨区块链分析中的过度拟合挑战,并提出一些解决方案。
过度拟合被认为是现代深度学习应用程序中的最大挑战之一。从概念上讲,当模型生成的假设过于适合特定数据集的假设而无法适应新数据集时,就会发生过度拟合。理解过度拟合的一个有用类比是将其视为模型中的幻觉。本质上,模型从数据集中推断出错误的假设时会产生幻觉/过度拟合。自从机器学习的早期以来,已经有很多关于过拟合的文章,所以我不认为有任何聪明的方法来解释它。对于区块链数据集,过度拟合是缺少标记数据的直接结果。
区块链是大型的半匿名数据结构,其中的所有事物都使用一组通用的构造表示,例如交易,地址和区块。从这个角度来看,有最少的信息可以证明区块链记录。这是转账还是付款交易?这是个人投资者钱包或交易所冷钱包的地址?这些限定符对于机器学习模型至关重要。
想象一下,我们正在创建一个模型来检测一组区块链中的交换地址。这个过程需要我们使用现有的区块链地址数据集训练模型,我们都知道这不是很常见。如果我们使用来自EtherScan或其他来源的小型数据集,则该模型可能会过度拟合并做出错误的分类。
美国三大股指跌幅均超1%:2月4日消息,道琼斯指数跌超1%,下跌340点,纳斯达克指数跌2.64%,标普500指数跌1.73%。[2022/2/4 9:30:37]
使过拟合变得如此具有挑战性的方面之一是很难在不同的深度学习技术中进行概括。卷积神经网络倾向于形成过拟合模式,该模式与观察到的与生成模型不同的递归神经网络不同,该模式可以外推到任何类型的深度学习模型。具有讽刺意味的是,过度拟合的倾向随着深度学习模型的计算能力线性增加。由于深度学习主体几乎可以免费产生复杂的假设,因此过拟合的可能性增加了。
在机器学习模型中,过度拟合是一个持续的挑战,但是在使用区块链数据集时,这几乎是必然的。解决过度拟合的明显答案是使用更大的训练数据集,但这并不总是一种选择。在IntoTheBlock,我们经常遇到过度拟合的挑战,我们依靠一系列基本方法来解决问题。
对抗区块链数据集过拟合的三种简单策略
对抗过度拟合的第一个规则是认识到这一点。虽然没有防止过度拟合的灵丹妙药,但实践经验表明,一些简单的,几乎是常识的规则可以帮助防止在深度学习应用中出现这种现象。为了防止过度拟合,已经发布了数十种最佳实践,其中包含三个基本概念。
数据/假设比率
当模型产生太多假设而没有相应的数据来验证它们时,通常会发生过度拟合。因此,深度学习应用程序应尝试在测试数据集和应评估的假设之间保持适当的比率。但是,这并不总是一种选择。
LBank蓝贝壳于4月13日22:00启动等值50,000USDT的MINA售卖:据悉,LBank将于4月13日22:00启动等值50,000USDT的Mina Protocol(MINA)代币售卖。本次总售卖数量为200,000枚MINA,售卖价格为0.25USDT。本次售卖分“LBK专场”和“USDT专场”两场,售卖认购模式为加权均分模式,用户需持有相应的USDT及LBK。
Mina是一个公共的,去中心化的区块链,个人或公司可以通过成为节点或块生产者来帮助提高网络的安全性,或者可以通过成为SNARK生产者来帮助降低交易成本,或者两者都可以。[2021/3/31 19:33:09]
有许多深度学习算法(例如归纳学习)依赖于不断生成新的,有时是更复杂的假设。在这些情况下,有一些统计技术可以帮助估计正确的假设数量,以优化找到接近正确的假设的机会。尽管此方法无法提供确切的答案,但可以帮助在假设数量和数据集组成之间保持统计平衡的比率。哈佛大学教授莱斯利·瓦利安特(Leslie Valiant)在他的《大概是正确的》一书中出色地解释了这一概念。

进行区块链分析时,数据/假设比率非常明显。假设我们正在基于一年的区块链交易构建预测算法。因为我们不确定要测试哪种机器学习模型,所以我们使用了一种神经架构搜索(NAS)方法,该方法针对区块链数据集测试了数百种模型。假设数据集仅包含一年的交易,则NAS方法可能会产生一个完全适合训练数据集的模型。
支持简单假设
防止深度学习模型过度拟合的概念上琐碎但技术上困难的想法是不断生成更简单的假设。当然!简单总是更好,不是吗?但是在深度学习算法的背景下,一个更简单的假设是什么?如果我们需要将其减少到一个定量因素,我会说深度学习假设中的属性数量与它的复杂度成正比。
简单的假设往往比其他具有大量计算和认知属性的假设更易于评估。因此,与复杂模型相比,较简单的模型通常不易过拟合。现在,下一个明显的难题是弄清楚如何在深度学习模型中生成更简单的假设。一种不太明显的技术是基于估计的复杂度将某种形式的惩罚附加到算法上。该机制倾向于倾向于更简单,近似准确的假设,而不是在出现新数据集时可能会崩溃的更复杂(有时甚至更准确)的假设。
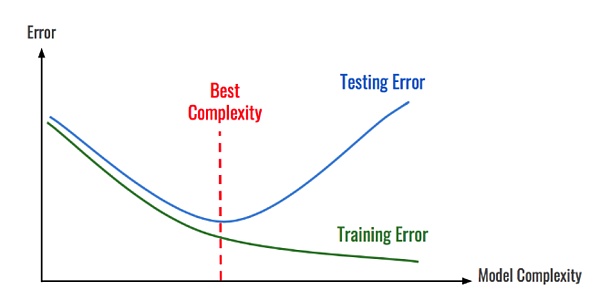
为了在区块链分析的背景下解释这个想法,让我们想象一下我们正在建立一个模型,用于对区块链中的支付交易进行分类。该模型使用一个复杂的深度神经网络,该网络会生成1000个特征以执行分类。如果将其应用于较小的区块链(例如Dash或Litecoin),则该模型很可能会过拟合。
偏差/方差余额
偏差和方差是深度学习模型中的两个关键估计量。从概念上讲,偏差是模型的平均预测与我们试图预测的正确值之间的差。具有高偏差的模型很少关注训练数据,从而简化了模型。总是会导致培训和测试数据的错误率很高。或者,方差是指给定数据点的模型预测的可变性或一个告诉我们数据分布的值。具有高方差的模型将大量注意力放在训练数据上,并且没有对以前从未见过的数据进行概括。结果,这样的模型在训练数据上表现很好,但是在测试数据上有很高的错误率。
偏差和方差与过度拟合如何相关?用超简单的术语来说,可以通过减少模型的偏差而不增加其方差来概括泛化的技巧。深度学习的一种良好做法是对它进行建模,以定期将产生的假设与测试数据集进行比较并评估结果。如果假设继续输出相同的错误,则说明我们存在很大的偏差问题,需要调整或替换算法。相反,如果没有明确的错误模式,则问题在于差异,我们需要更多数据。
综上所述
? 任何低复杂度模型-由于高偏差和低方差,容易出现拟合不足。
? 任何高复杂度模型(深度神经网络)-由于低偏差和高方差,容易出现过度拟合。

在区块链分析的背景下,偏差方差摩擦无处不在。让我们回到我们的算法,该算法尝试使用许多区块链因素来预测价格。如果我们使用简单的线性回归方法,则该模型可能不合适。但是,如果我们使用具有少量数据集的超复杂神经网络,则该模型可能会过拟合。
使用机器学习来分析区块链数据是一个新生的空间。结果,大多数模型在机器学习应用程序中都遇到了传统挑战。根本上,由于缺乏标记数据和训练有素的模型,过度拟合是区块链分析中无所不在的挑战之一
美国证券交易委员会(SEC)向纽约南区法院提交了一份备忘录,称Telegram计划发行的Gram代币没有内在价值。 SEC在该公开文件中称,“Telegram试图将Gram代币归类为‘商品’。但是Gram不是商品,与黄金、漫画书和甜甜圈不同,Gram没有内在价值。
“食品溯源、电子发票、物流跟踪、跨境支付……”2019年,区块链去中心化、可追溯、防篡改等硬核实力逐渐被挖掘,它不再是比特币的代名词,而正成为赋能千行百业的“利器”。 步入2020年,在政策的驱动下,随着各行业的高度重视以及领先科技企业入局,区块链技术将持续优化,并与人工智能、大数据等多种技术融合创新。
印度关于区块链和分布式账本技术的国家战略草案提出了中央银行数字货币(CBDC)、印度数字卢比和国家区块链的构想。 印度政府成立的非盈利公共机构国家智能治理研究所(NISG)公布了印度国家区块链战略文件草案。
当互联网处在最初发展阶段时,大家都认为它可以改变世界,却不知道如何才能实现它的大规模商用。最终,是集成电路技术的迅猛发展扭转了这一局面,硬件设施的提升让互联网成功落地,芯片技术也作为最重要的物质基础,一路保障着互联网的加速发展。区块链如今面临的状况,和互联网刚刚诞生时极为相似,落地是最大的问题,性能是瓶颈所在。
谈到区块链,不得不提的一个概念便是“算力”。本文以BOINC(伯克利开放式网络计算平台)为例,讲解了区块链对于算力行业的意义。 作者认为BOINC改造方案是对原有基于志愿基础上的算力贡献进行了通证化处理,在技术层面针对BOINC的算力分配和调度进行了优化。文中有较为硬核的知识点,案例介绍的形式使得本篇内容更易懂。
今年是“减产”风口,各种主流都提升了难度,但是他们的减产总量还是没有变化,而为了做到真正意义上的总量减少,TGIC-全球指数链在2020年2月14日将对主网升级4.0,同时销毁4.5亿枚TGIC。TGIC原发行10亿枚,其中3亿是需要几十年释放给排名在前23名的超级节点,当前释放了800多万枚。