如何准确预测加密货币价格?这篇内容了解下
巴比特资讯
刚刚
25
原标题:《加密货币价格预测:交易,技术和社交情绪指标的深度学习研究》
币圈深度参与者和holder获得更高收益,而不是trader,这或许是我们的错觉,因为加密货币资产天然适合种套利高频机器人交易。
虽然像我们这些有点信仰又不是老炮的散户韭菜,对交易技术指标有点不屑。但面对币价波动,我们也不那么佛系,价格涨跌或多或少扰乱我们的情绪。
而对于币价的预测或感觉,仅凭社交情绪。本文从大量的技术,交易,社交情绪指标通过各种深度学习算法得出的结论是,综合技术,交易,社交情绪指标的深度学习结果对预测币价比单一指标要好。而Github和Reddit的基于技术开发人员的情绪指标更具有参考价值。
虽然这不一定正确更不是真理,毕竟深度学习算法和数据都可能有问题。然而这足足30来页的论文足已令我们恐惧,如今能用到如此高深的算法和有如此开放丰富的数据对加密资产交易预测,我们散户韭菜如何是好?
也许只有做好个人功课。我们为什么要投资这个项目?我们如何能为项目贡献?我如何才能不在乎币价?
摘要
由于加密货币市场的高波动性和新机制的存在,预测加密货币的价格是一项众所周知的艰巨任务。在这项工作中,我们重点研究了2017-2020年期间两种主要加密货币以太坊和比特币。通过比较四种不同的深度学习算法、卷积神经网络、长短期记忆神经网络和注意长短期记忆)和三类特征,对价格波动的可预测性进行了综合分析。特别是,我们考虑将技术指标、交易指标和社交指标作为分类算法的输入。我们比较了一个仅由技术指标组成的受限模型和一个包括技术、交易和社交媒体指标的非受限模型。结果表明,不受限制的模型优于受限制的模型,即包括交易和社交媒体指标,以及经典的技术变量,使得所有算法的预测精度都有显著提高。
1简介
在过去十年中,全球市场见证了加密货币交易的兴起和指数增长,全球每日市值达数千亿美元。
最近的调查显示,尽管存在价格波动和市场操纵相关的风险,但机构投资者对新加密资产的需求和兴趣仍在飙升,原因是这些资产的新特性以及当前金融风暴中潜在的价值上升。
繁荣和萧条周期往往由网络效应和更广泛的市场采用引起,使价格难以高精度预测。关于这一问题有大量文献,并提出了许多加密货币价格预测的定量方法。加密货币的波动性、自相关和多重标度效应的快速波动也得到了广泛的研究,同时也研究了它们对初始硬币发行的影响。
文献中逐渐出现的一个重要考虑因素是加密货币交易的“社会”的相关性。区块链平台的底层代码在Github上以开源方式开发,加密生态系统的最新添加内容在Reddit或Telegram的专业频道上讨论,Twitter提供了一个经常就最新发展进行激烈辩论的平台。更准确地说,已经证明,情绪指数可以用来预测价格泡沫,而且从Reddit专题讨论中提取的情绪与价格相关。
开源开发在塑造加密货币的成功和价值方面也扮演着重要的角色。特别是,Bartoluccietal.之前的一项工作表明,从开发人员对Github的评论中提取的情绪时间序列与加密货币的回报之间存在格兰杰因果关系。对于比特币和以太坊这两种主要的加密货币,还显示了如何将开发者的情绪时间序列纳入预测算法中,从而大大提高预测的准确性。
在本文中,我们使用深度学习方法进一步扩展了以前对价格可预测性的研究,并将重点放在按市值最高的两种主要加密货币,比特币和以太坊。
我们通过将准时价格预测映射到一个分类问题来预测价格变动:我们的目标是一个具有两个独特类别的二元变量,向上和向下的变动,表示价格上涨或下跌。下面我们将比较四种深度学习算法的性能和结果:多层感知器、多变量注意长短时记忆完全卷积网络、卷积神经网络和长短时记忆神经网络。
我们将使用以下类别的指标作为输入:技术指标,如开盘和收盘价格或成交量,交易指标,如根据价格计算的动量和移动平均线,社交媒体指标,即从Github和Reddit评论中提取的情绪要素。
对于每一个深度学习算法,我们考虑一个按小时和按每天频率的受限和非受限数据模型。受限模型由比特币和以太坊的技术变量数据组成。在无限制模型中,我们包含了Github和Reddit的社交媒体指标和技术、交易变量。
在所有四种深度学习算法中,我们都能证明无限制模型优于限制模型。在每小时数据频率下,将交易和社交媒体指标与经典技术指标结合起来,能提高比特币和以太坊价格预测的准确性,从限制模式的51-55%提高到非限制模式的67-84%。对于每日频率分辨率,在以太坊的情况下,使用限制模型实现最精确的分类。相反,对于比特币而言,仅包括社交媒体指标的无限制模式实现了最高的性能。
在下面的部分中,我们将详细讨论实现的算法和用于评估模型性能的引导验证技术。
本文的结构如下。在第2节中,我们详细描述了使用的数据和指标。在第三节中,我们讨论了实验的方法。在第4节中,我们介绍了研究结果及其意义,在第5节中,我们讨论了本研究的局限性。最后,在第6节中,我们总结了我们的发现并概述了未来的发展方向。
2数据集:技术和社交媒体指标
本节讨论数据集和用于实验的三类指标。
2.1技术指标
我们以每小时和每天的频率对比特币和以太坊价格时间序列进行了分析。我们从加密数据下载web服务中提取的所有可用技术变量,特别是来自Bitfinex.com网站交易数据服务。我们考虑了过去4年,从2017/01/01到2021/01/01,共35,638个小时的观测值。
市场分析:欧洲央行的新通胀目标仍没有回答如何实现的问题:Gruener Fisher Investments创始人Thomas Gruener表示,欧洲央行新的对称通胀目标“很好”,但市场更感兴趣的是欧洲央行会对此采取什么行动。因此,路线图并没有变得更加具体,与过去几年的‘非常规货币政策’的区别仅限于措辞上的细微之处。他表示,这些含糊的声明表明,欧洲央行根本无法精确实现其通胀目标。在这方面,欧洲央行与美联储、英国央行和日本央行是相同的。[2021/7/15 0:55:11]
在我们的分析中,我们将技术指标分为两大类:纯技术指标和交易指标。技术指标指的是开盘价和收盘价等“直接”的市场数据。交易指标是指移动平均线等衍生指标。
技术指标如下:
收盘价:加密货币在交易期间的最后交易价格。
开盘价:加密货币在交易期开始时首次交易的价格。
最低:加密货币在一个交易周期内交易的最低价格。
最高:加密货币在交易期间交易的最高价格。
交易量:完成的加密货币交易数量。
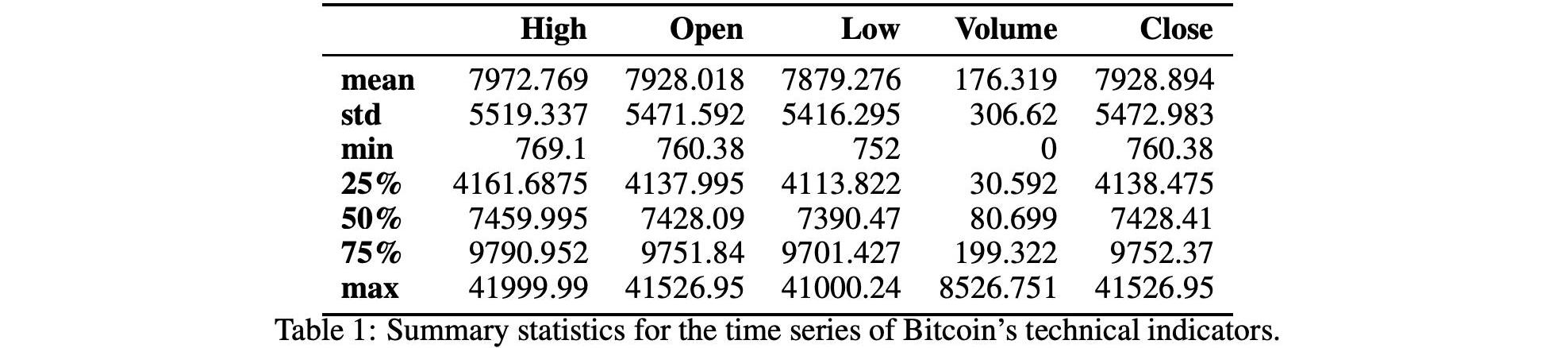
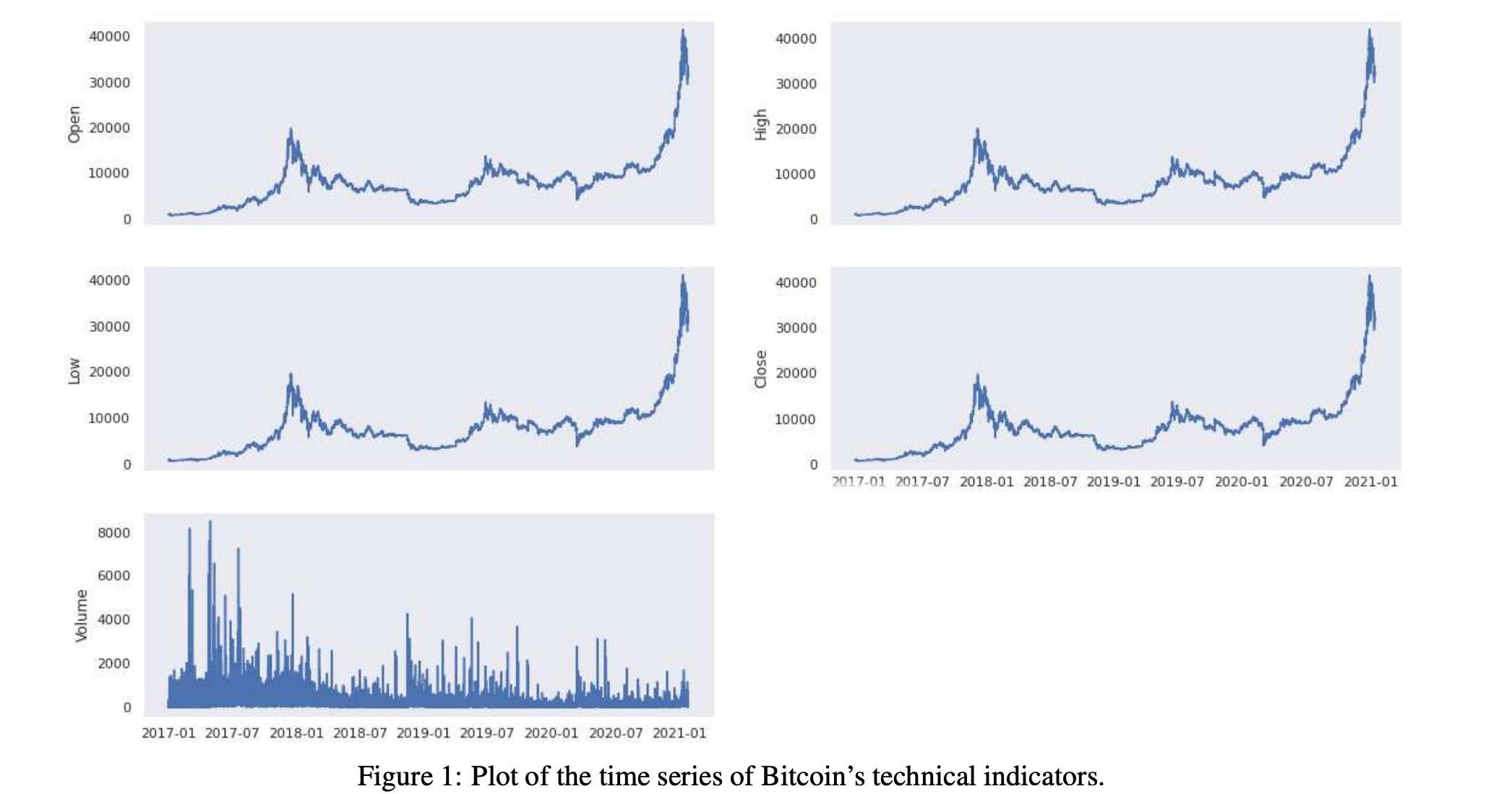
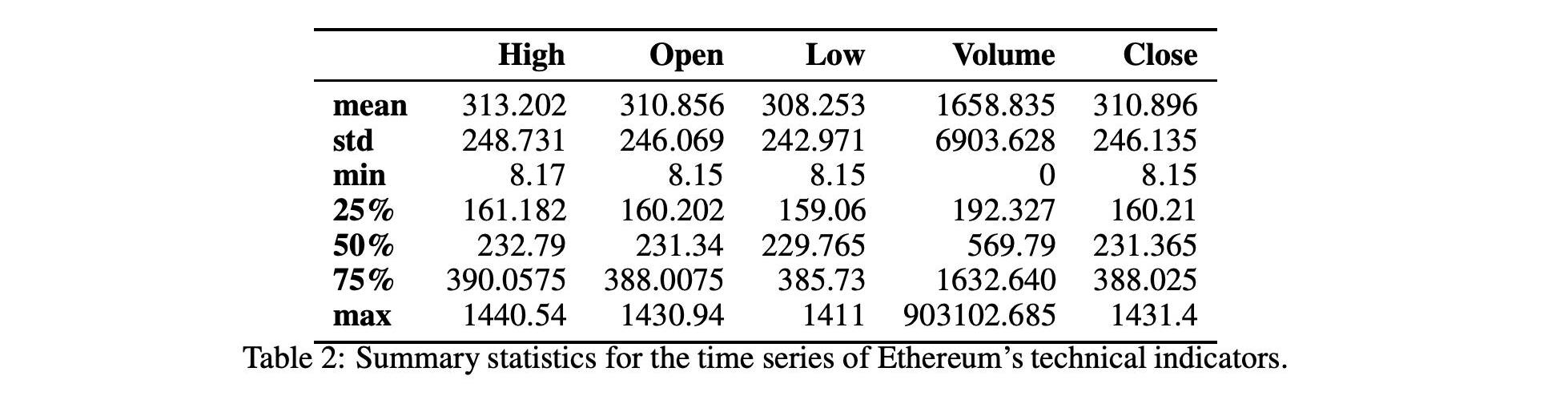
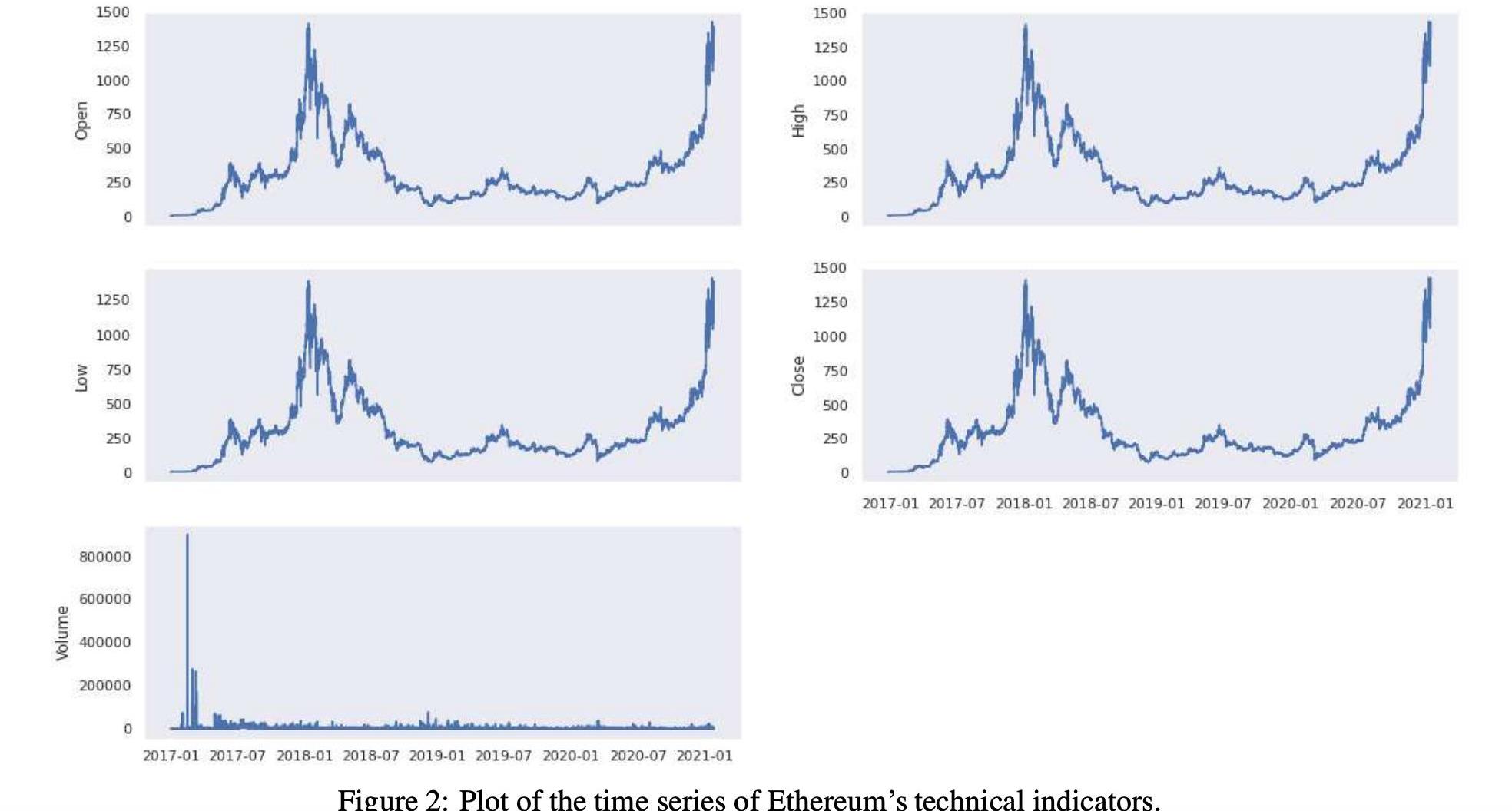
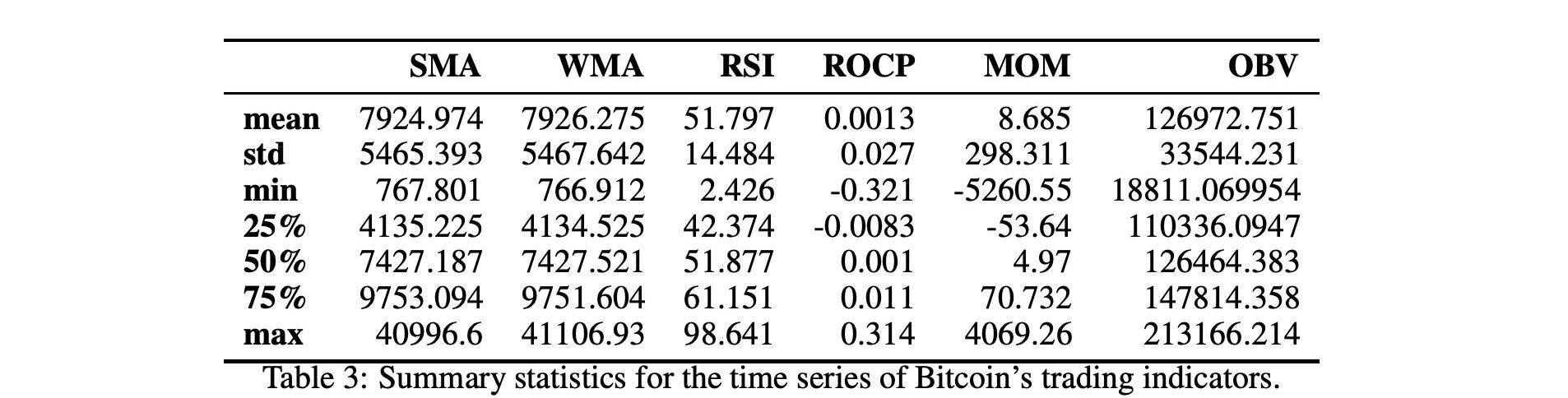
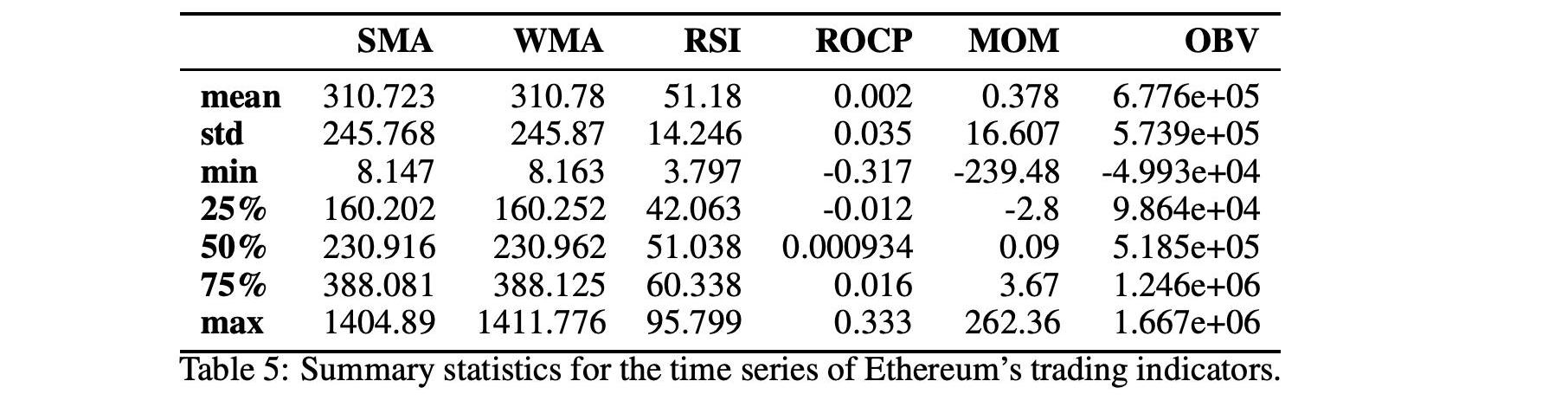
表1和表2显示了技术指标的汇总统计数字。在图1和图2中,我们还显示了技术指标的历史时间序列图。
根据对这些技术指标,可以计算交易指标,如移动平均值。更准确地说,我们使用StockStatsPython库来生成它们。
我们使用了36个不同的交易指标,如表4所示。滞后值表示以前的值用作输入。窗口大小表示用于在时间t评估指标的先前值的数目,例如,为了计算时间t的ADXRt,我们使用ADXt?1,…,ADXRt?10,十个先前值。
我们在这里提供五个主要交易指标的定义。
简单移动平均:加密货币在某一时期收盘价的算术平均值。
加权移动平均:移动平均计算,为最新的价格数据赋予更高的权重。
相对强度指数:是衡量近期价格变化幅度的动量指标。它通常用于评估股票或其他资产是否超买或超卖。
价格变化率:衡量当前价格与一定时期前价格之间的百分比变化。
动量:是价格的加速率,即价格变化的速度。这一措施对于确定趋势特别有用。
平衡成交量:是基于资产交易量的技术动量指标,用于预测股价变化。
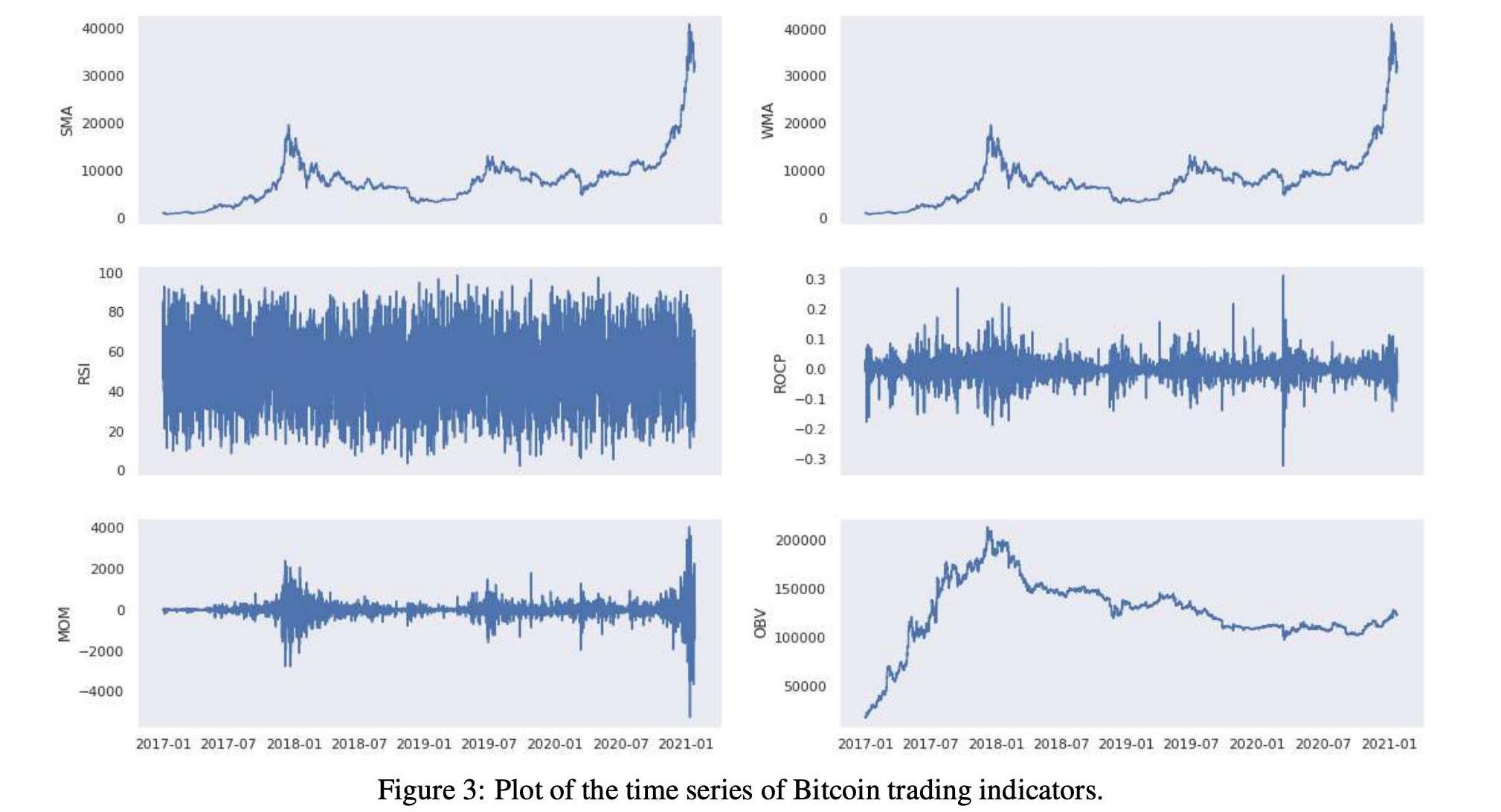
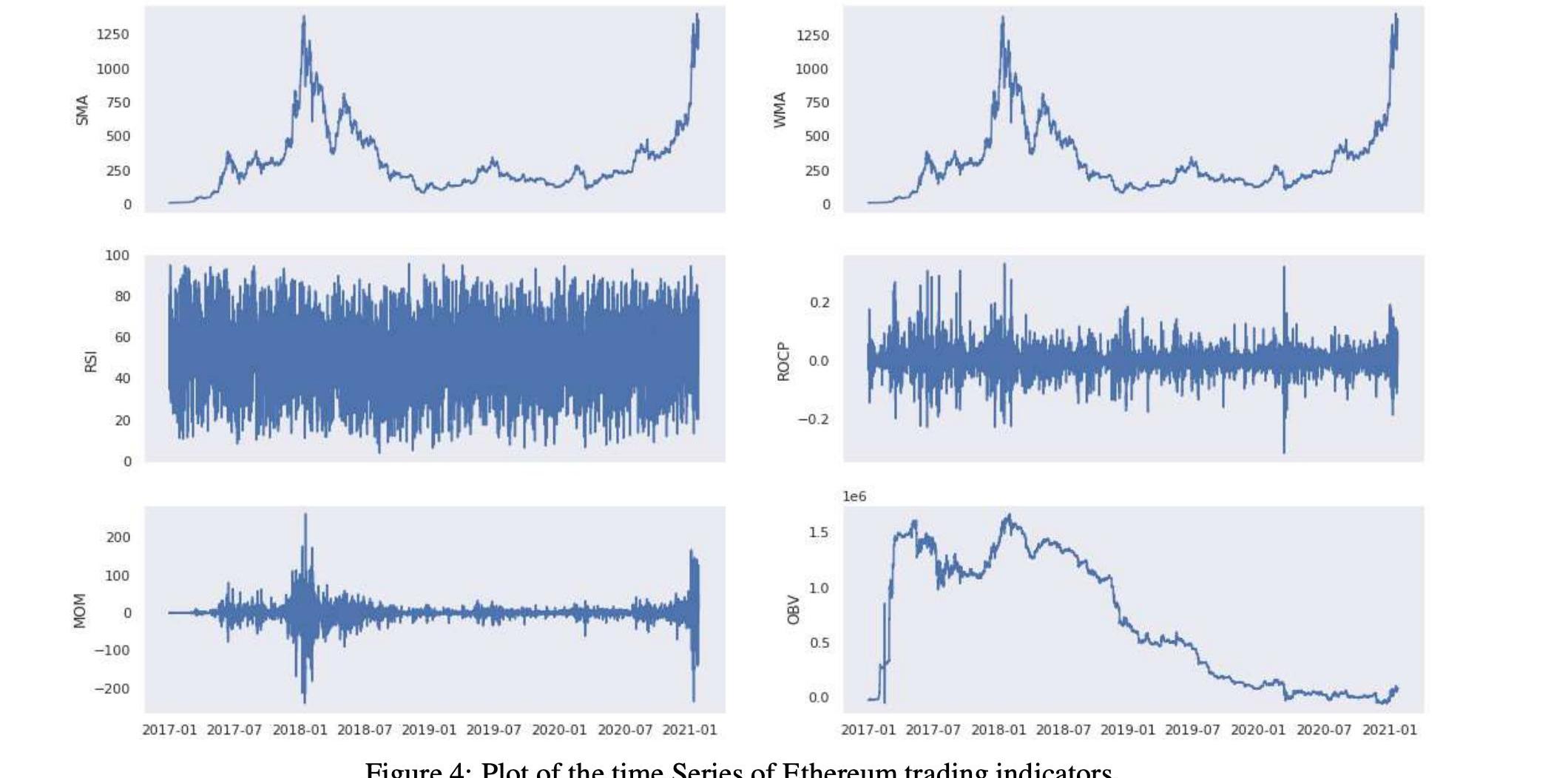
表3和表5显示了所考虑的分析期间的交易指标统计数字。在图3和图4中,我们可以在历史时间序列图中看到相同的交易指标。下一节将使用技术和交易指标来创建价格分类模型。

2.2社交媒体指标
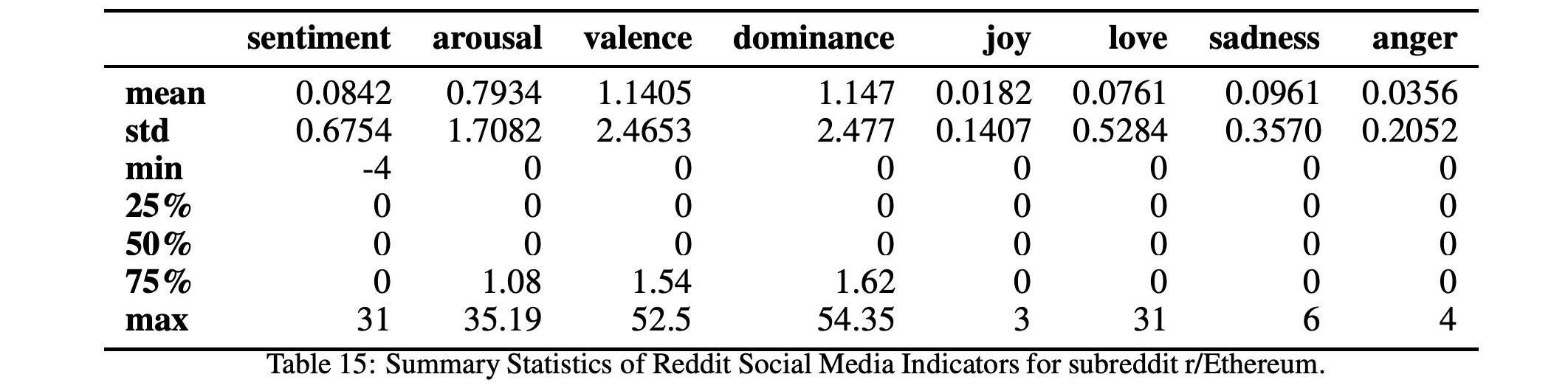
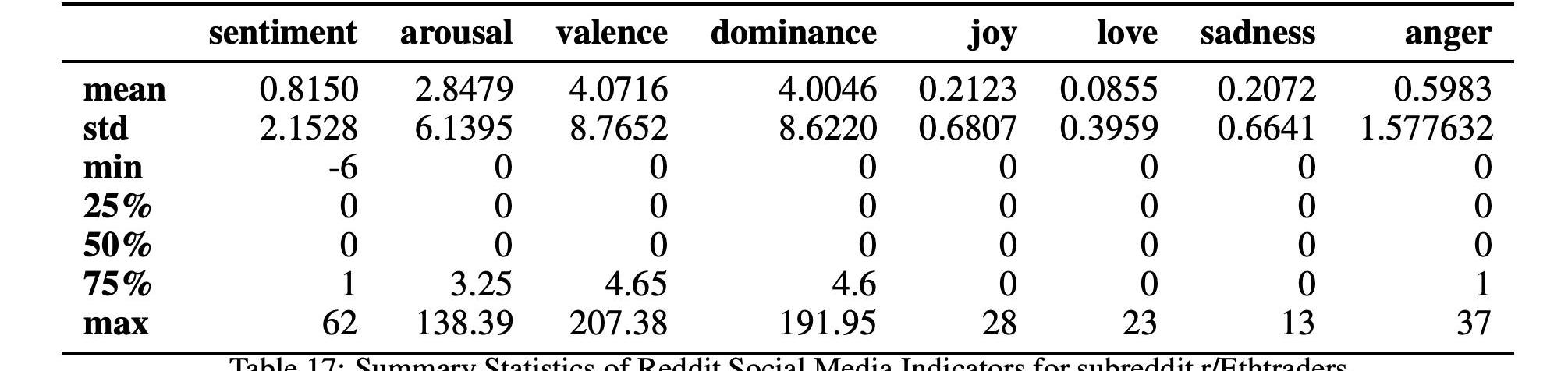
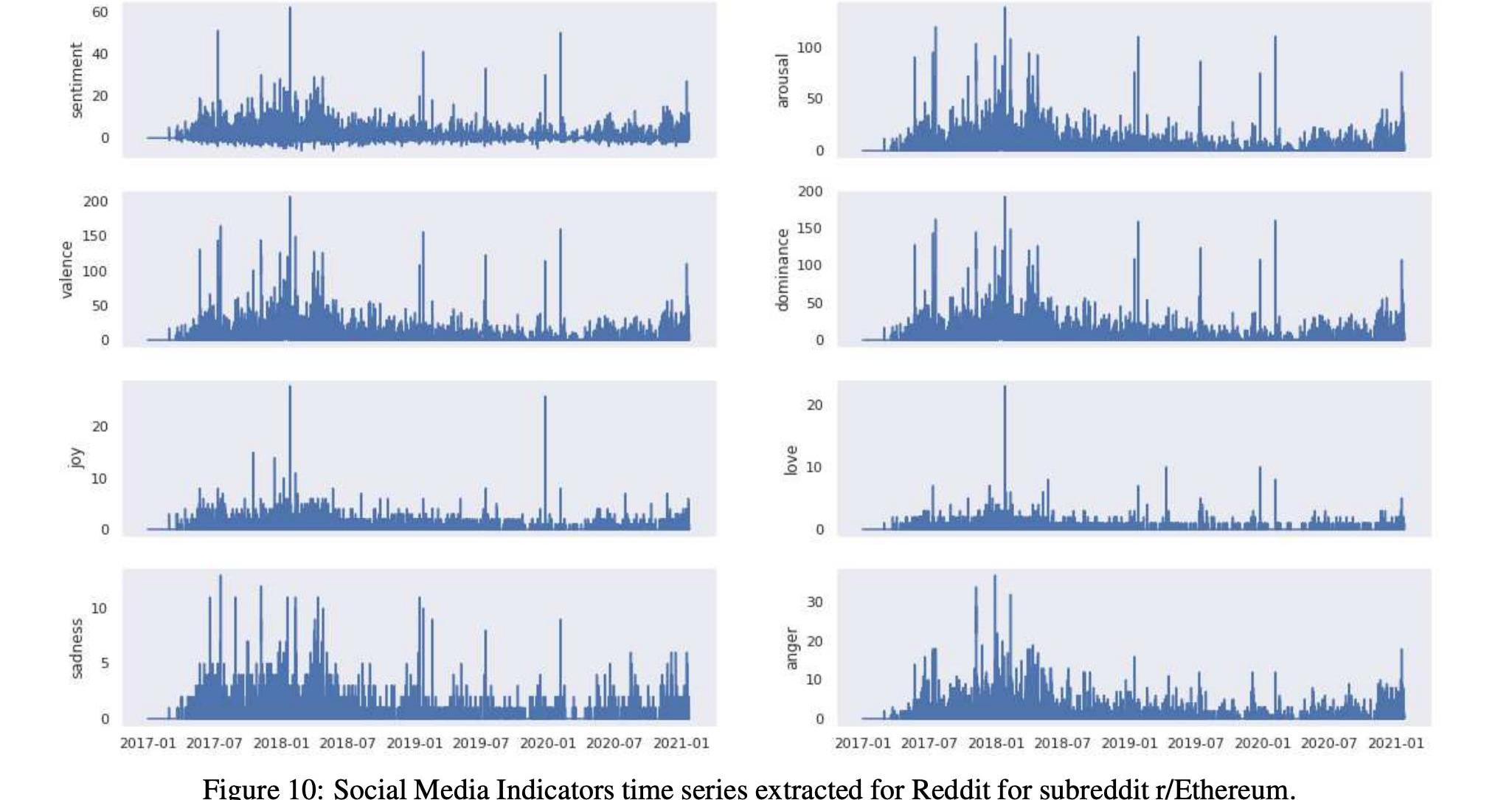
本节描述了社交媒体指标的时间序列是如何分别从以太坊和比特币开发者对Github的评论和用户对Reddit的评论构建的。特别是,对于Reddit,我们考虑了表6中列出的四个子Reddit通道。考虑的时间段为2017年1月至2021年1月。

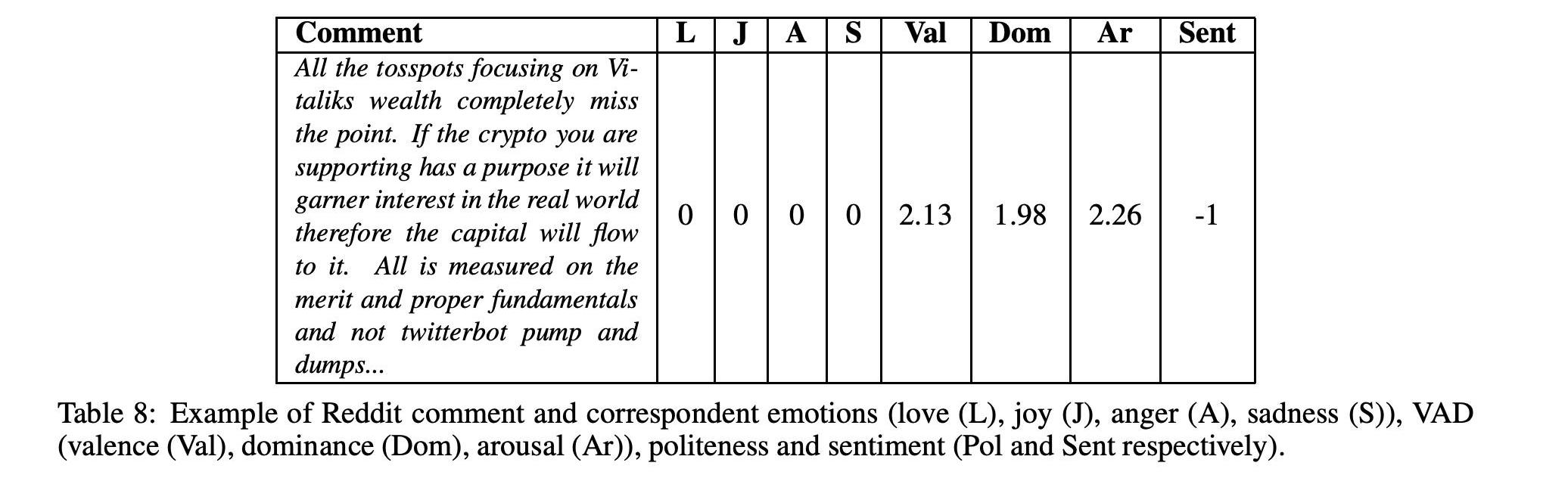
从GithubforEthereum中提取的开发人员注释和从Redditr/Ethereum中提取的用户注释的示例可以在表7和表8中看到。如本例所述,与评论相关的情绪的定量度量是使用最先进的文本分析工具计算的。为每条评论计算的这些社交媒体指标是情感,如爱、快乐、愤怒、悲伤、VAD、支配、唤醒)和情感。

2.3通过深度学习评估社交媒体指标
我们使用深度、预训练的神经网络从BERT模型中提取社交媒体指标,称为双向编码器表示。BERT和其他转换器编码器结构已经成功地运行在自然语言处理中的各种任务,代表了自然语言处理中常用的递归神经网络的发展。他们计算适合在深度学习模型中使用的自然语言的向量空间表示。BERT系列模型使用Transformer编码器体系结构在所有标记前后的完整上下文中处理输入文本的每个标记,因此得名:Transformers的双向编码器表示。BERT模型通常是在一个大的文本语料库上进行预训练,然后针对特定的任务进行微调。这些模型通过使用一个深度的、预先训练的神经网络为自然语言提供了密集的向量表示,较换器结构如图5所示。
电商巨头Shopify CEO正考虑如何将Shopify与DeFi生态系统整合:电商巨头Shopify首席执行官Tobi Lutke正在考虑如何将其公司与去中心化金融(DeFi)生态系统整合。Lutke昨日在推特上发布了一条消息,询问DeFi社区Shopify在日益增长的金融领域中可以扮演什么“角色”。(Cointelegraph)[2021/4/4 19:43:56]
转换器基于注意力机制,RNN单元将输入编码到一个隐藏向量ht,直到时间戳t。后者随后将被传递到下一个时间戳。通过使用注意力机制,人们不再试图将完整的源语句编码成一个固定长度的向量。相反,在输出生成的每个步骤中,允许解码器处理源语句的不同部分。重要的是,我们让模型根据输入的句子以及到目前为止它产生了什么来学习要注意什么。
Transformer体系结构允许创建在非常大的数据集上训练的NLP模型,正如我们在这项工作中所做的那样。由于预先训练好的语言模型可以在特定的数据集上进行微调,而无需重新训练整个网络,因此在大数据集上训练这样的模型是可行的。
通过广泛的预训练模型学习的权重,可以在以后的特定任务中重用,只需根据特定的数据集调整权重即可。这将允许我们通过捕获特定数据集的较低层次的复杂性,利用预先训练的语言模型通过更精细的权重调整所学到的知识。
我们在Transformer包中使用Tensorflow和KerasPython库来利用这些预训练神经网络的功能。特别地,我们使用了BERT基案例预训练模型。图6显示了用于训练用于提取社交媒体指标的三个NN分类器的体系结构设计。此图显示了用于训练最终模型的三个gold数据集,即Github、StackOverflow和Reddit。
特别是,我们使用了一个情感标签数据集,该数据集由从Stackoverflow用户评论中挖掘出来的4,423条帖子组成,用于训练Github的情感模型:两个平台上的评论都是使用软件开发人员和工程师的技术术语编写的。我们还使用了来自Github的4,200个句子的情感标记数据集。最后,我们使用了一个情感标签数据集,其中包含超过33K个标签Reddit用户的评论.
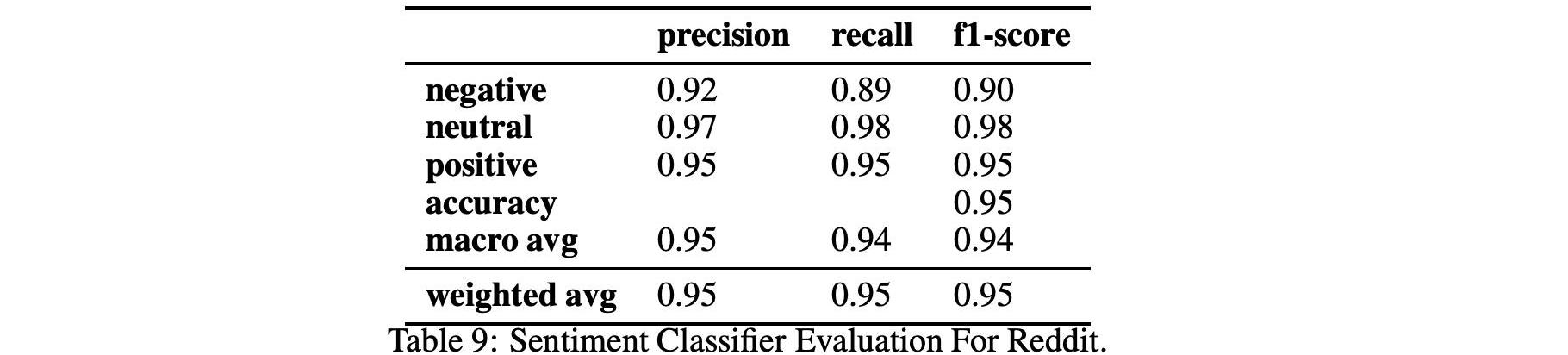
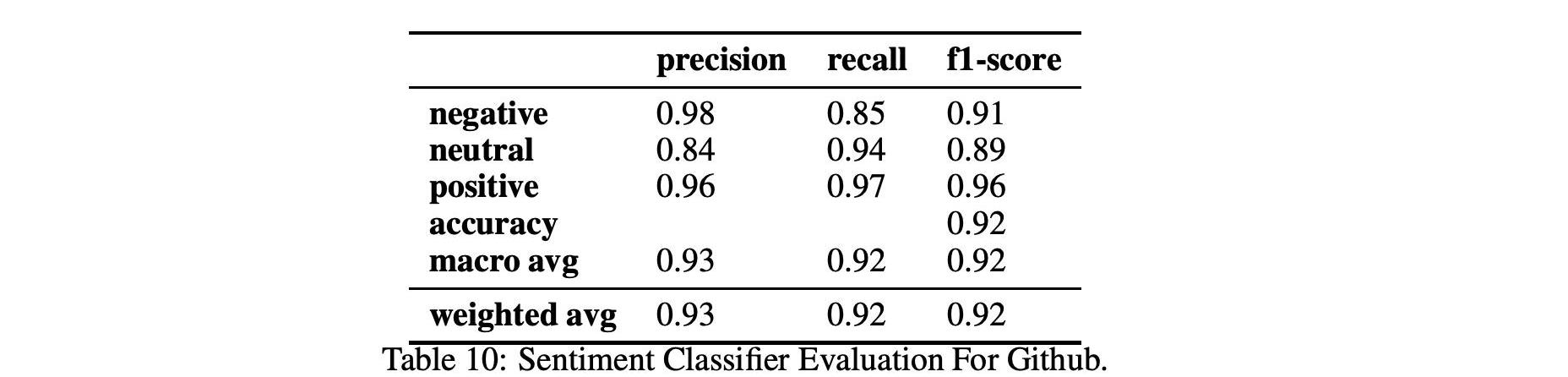
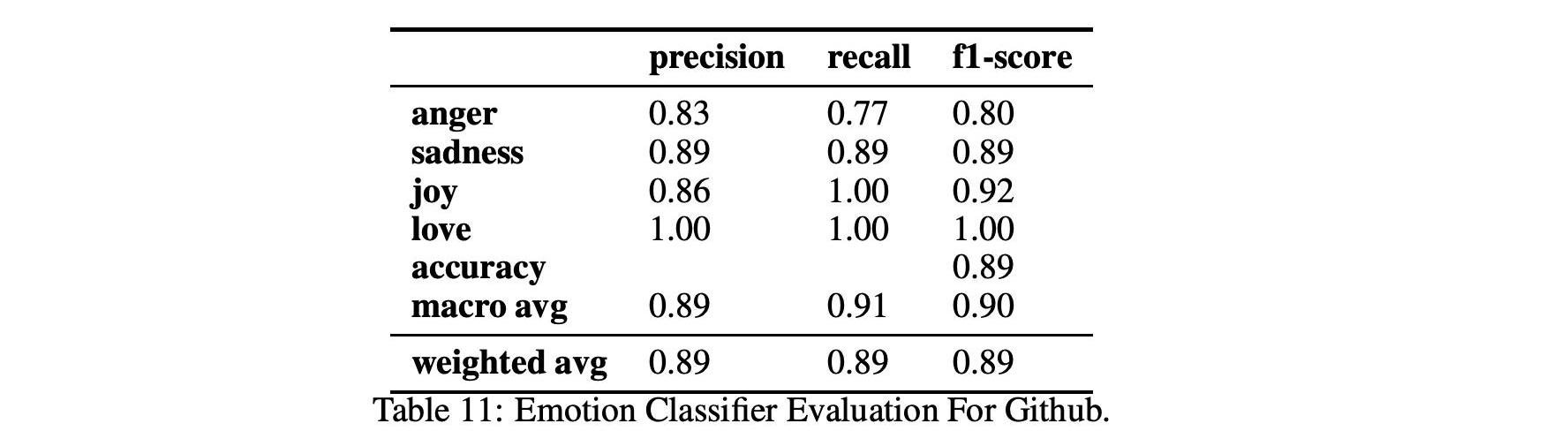
表9、10和11显示了情绪和情绪分类在两个不同数据集Github和Reddit上的性能。
2.3.1Github上的社交媒体指标
比特币和以太坊项目都是开源的,因此代码和贡献者之间的所有交互都可以在GitHub上公开获得。积极的贡献者不断地打开、评论和关闭所谓的“问题/issue”。问题是开发过程的一个元素,它包含有关发现的bug的信息、关于代码中要实现的新功能的建议、新特性或正在开发的新功能。它是跟踪所有开发过程阶段的一种优雅而有效的方法,即使在涉及大量远程开发人员的复杂和大型项目中也是如此。一个问题可以被“评论”,这意味着开发人员可以围绕它展开子讨论。他们通常会对某一特定问题添加评论,以强调正在采取的行动或就可能的解决方案提出建议。发布在GitHub上的每个评论都有时间戳;因此,可以获得准确的时间和日期,并为本研究中考虑的每个影响度量生成一个时间序列。
对于情绪分析,我们使用2.3中解释的BERT分类器,该分类器使用由Ortu等人开发并由Murgia等人扩展的公共Github情感数据集进行训练。这个数据集特别适合我们的分析,因为情绪分析算法是根据从Apache软件基金会的Jira问题跟踪系统中提取的开发人员评论进行训练的,因此在Github和Reddit的软件工程领域和上下文中。该分类器可以分析出爱、愤怒、喜悦和悲伤,F1得分接近0.89。
Valence、Arousal、Dominance就是所谓的VAD代表了概念化的情感维度,分别描述了受试者对特定刺激的兴趣、警觉性和控制感。在软件开发的上下文中,VAD度量可以表示开发人员对项目的参与程度,以及他们完成任务的信心和响应能力。Warriner等人创建了一个参考词典,其中包含14000个英语单词,其VAD分数可用于训练分类器,类似于Mantyla等人的方法。在中,他们从70万份Jira问题报告中提取了VAD指标,其中包含超过200万条评论,并表明不同类型的问题报告具有情绪变化。相比之下,问题优先级的增加通常会增加Arousal。
最后,使用2.3中解释的BERT分类器和类似研究中使用的公共数据集对情绪进行测量。该算法从正、中性和负三个层次提取短文本中表达的情感极性。
我们的分析主要集中在三类情感指标上:情感、VAD和情感。正如我们在第2.3节中指定的,我们使用定制的工具从每个影响度量类的注释文本中提取它。
一旦为所有评论计算了影响度量的数值,我们就会考虑评论时间戳来构建相应的社交媒体时间序列。情感时间序列是根据所考虑的时间频率在每小时和每天聚合多个评论的情感和情绪。
对于给定的社交媒体指标和特定的时间频率,我们通过平均当天发布的所有评论的影响度量值来构建时间序列。
声音 | 王小云:区块链技术创造性地解决了如何在无许可环境下达成共识的问题:12月7日,由中国科学院学部主办的“区块链技术与应用”科学与技术前沿论坛在深圳举行。中国科学院院士、国际密码协会会士王小云在题为“Hash函数与区块链技术”的演讲中表示,密码是保障网络与信息安全的核心技术和基础支撑,加密算法、数字签名算法和Hash函数是密码学三类基础算法,其中Hash函数是区块链的起源性技术。她指出,区块链技术的出现,创造性地解决了如何在无许可环境下达成共识的问题。区块链共识协议的一致性,确保了所有用户记录的区块链数据相同;链增长速度,确保了区块链区块数量增长速度的稳定;链质量,确保链区块链中敌手生成的区块数量不超过可容忍比例。[2019/12/7]
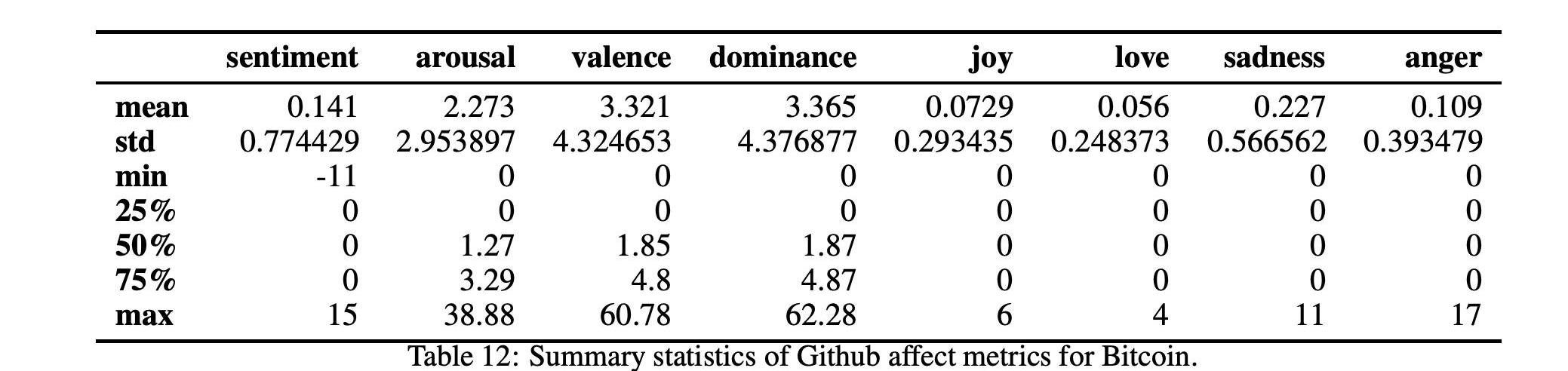
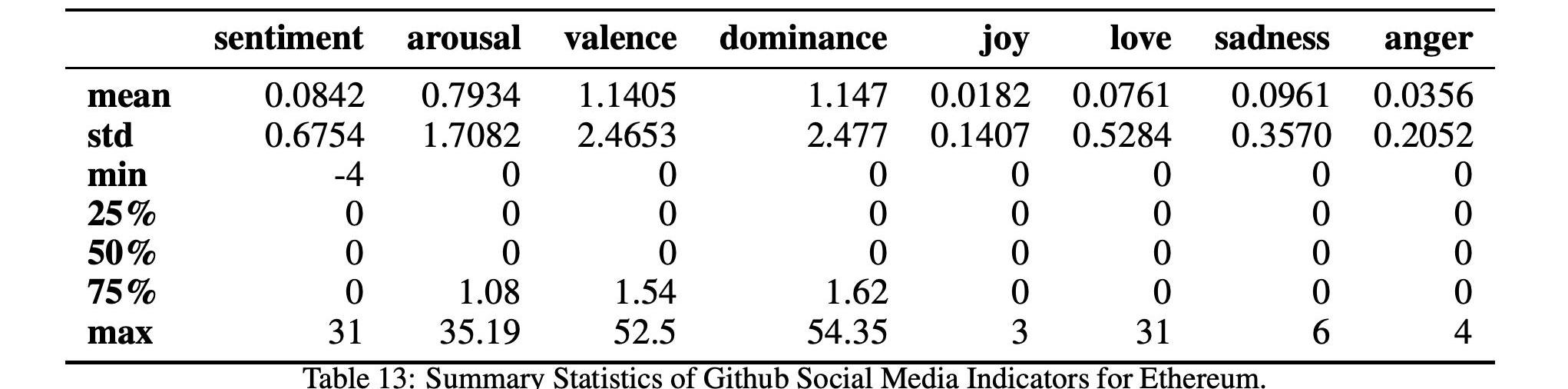
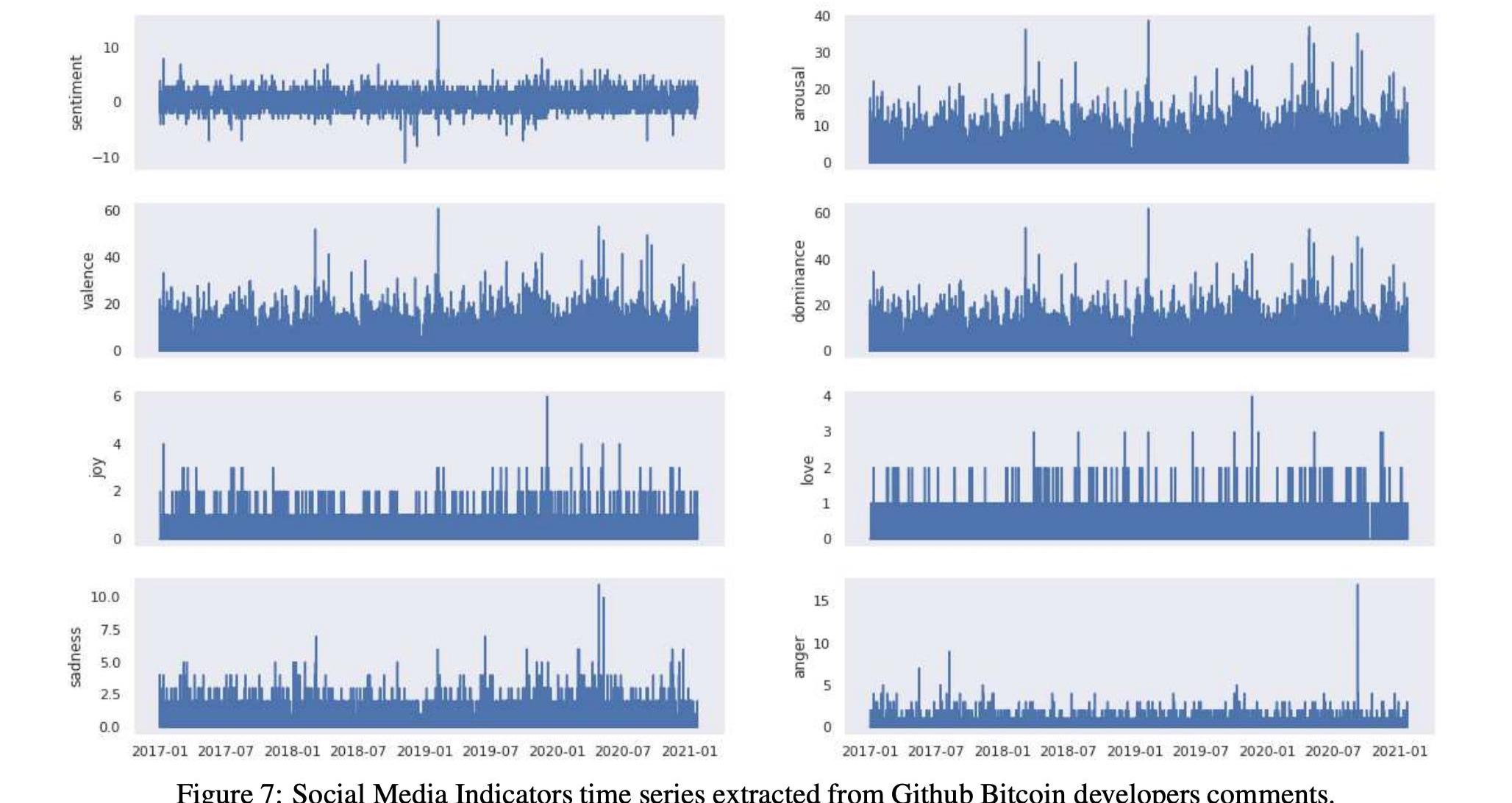
在表12和13中,我们分别详细报告了两种加密货币的社会指标时间序列的汇总统计数据。我们还在图7和图8中分别报告了比特币和以太坊的所有社交媒体指标的时间序列
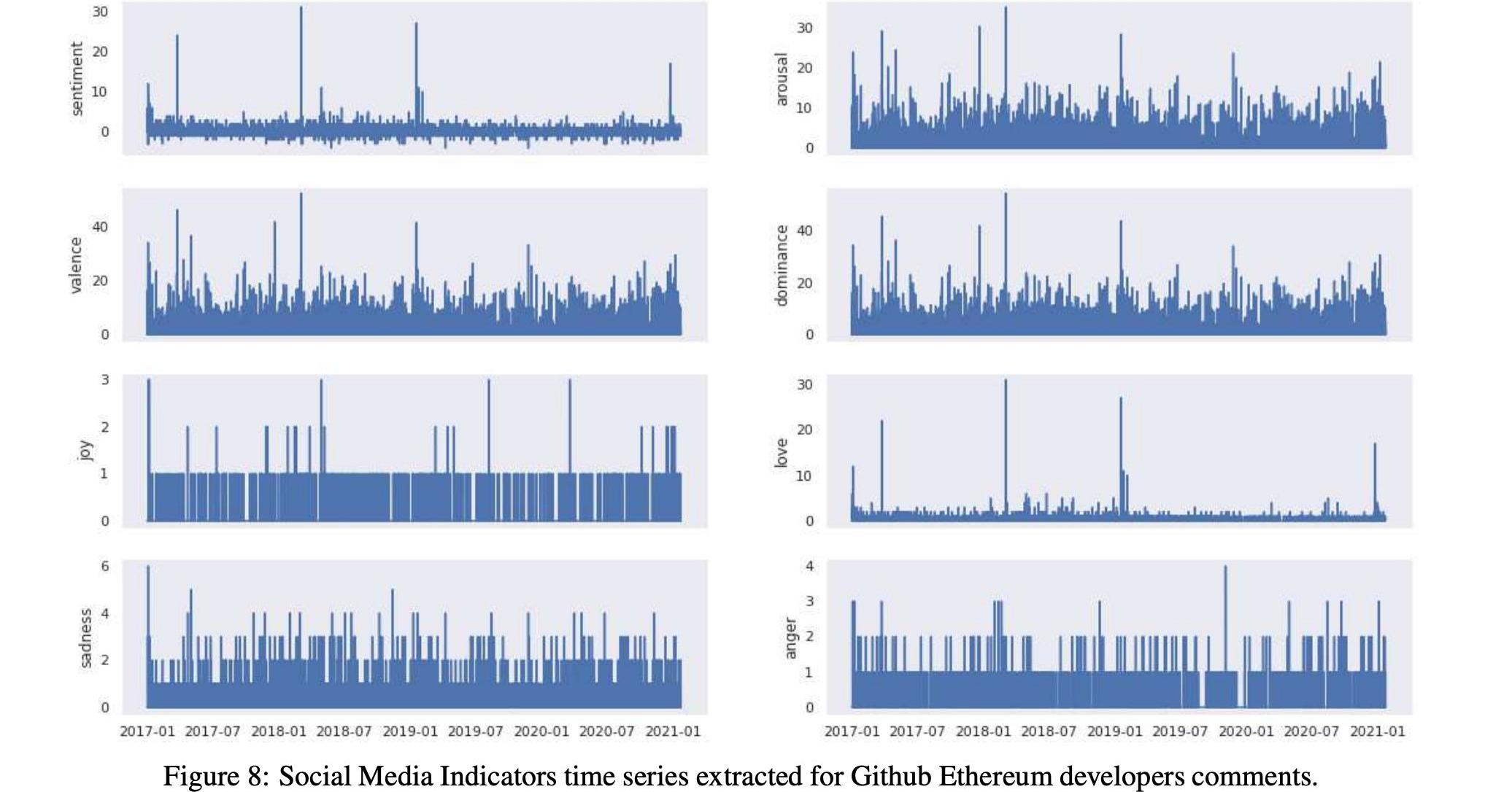
2.3.2测量Reddit的影响度量
社交媒体平台Reddit是一个美国社交新闻聚合、网络内容评级和讨论网站,每月访问量约80亿次。在英语国家,尤其是加拿大和美国,它是一个最受欢迎的社交网络。几乎所有的信息都是用英语写的,少数是用西班牙语、意大利语、法语和德语写的。
Reddit构建在多个子Reddit之上,每个子Reddit都致力于讨论特定的主题。因此,主要的加密货币项目有特定的子项。对于这项工作中的每一种加密货币,分析了两个子项,一个是技术性的,一个是交易相关的。在选项卡中,被考虑的子项。如图所示,对于每个subreddit,我们收集了从2017年1月到2021年1月的所有评论。
对于情感检测,我们使用2.3中解释的BERT分类器,该分类器使用由Ortu等人开发并由Murgia等人扩展的公共Github情感数据集进行训练。这个数据集特别适合我们的分析,如前一节所述。
该分类器可以检测出爱、愤怒、喜悦和悲伤,F1得分接近0.89。对于VAD指标,我们使用了2.3.1中相同的方法,而对于情绪,我们使用了之前的方法,即BERT深度学习算法,该算法使用了一个公共黄金数据集进行训练,用于在最大和知名的共享数据集的web平台上提供的Reddit评论Kaggle.com.
表14和16以及图9和11显示了这两个比特币子Reddits的统计数据和时间序列,
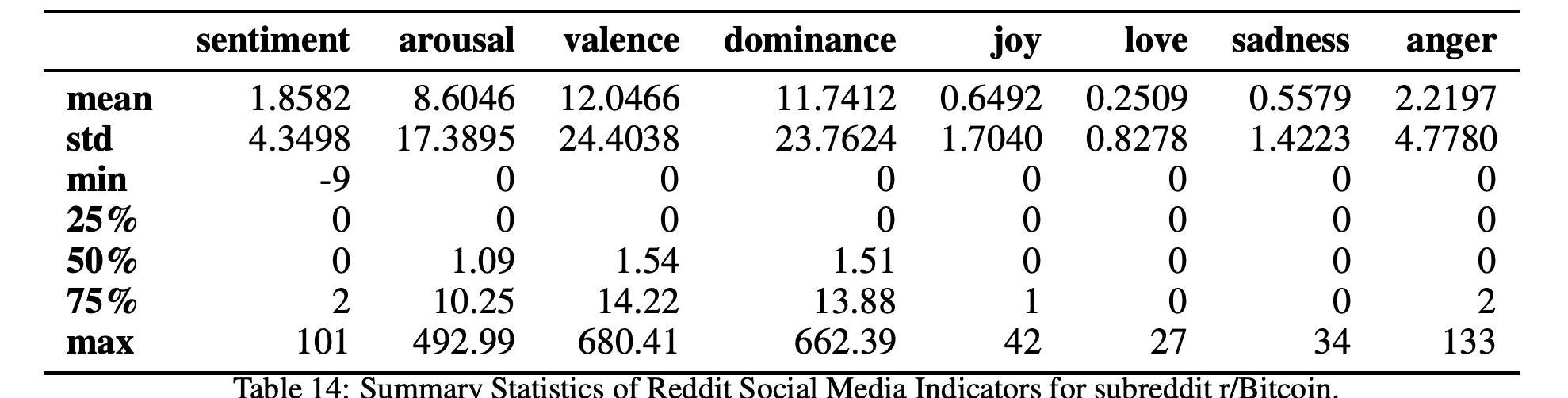
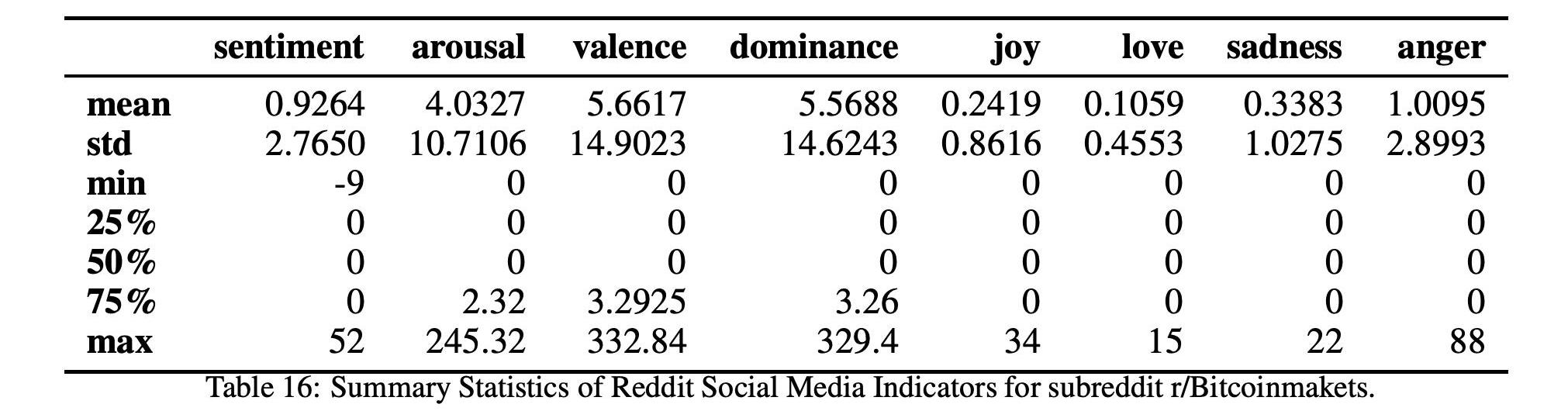
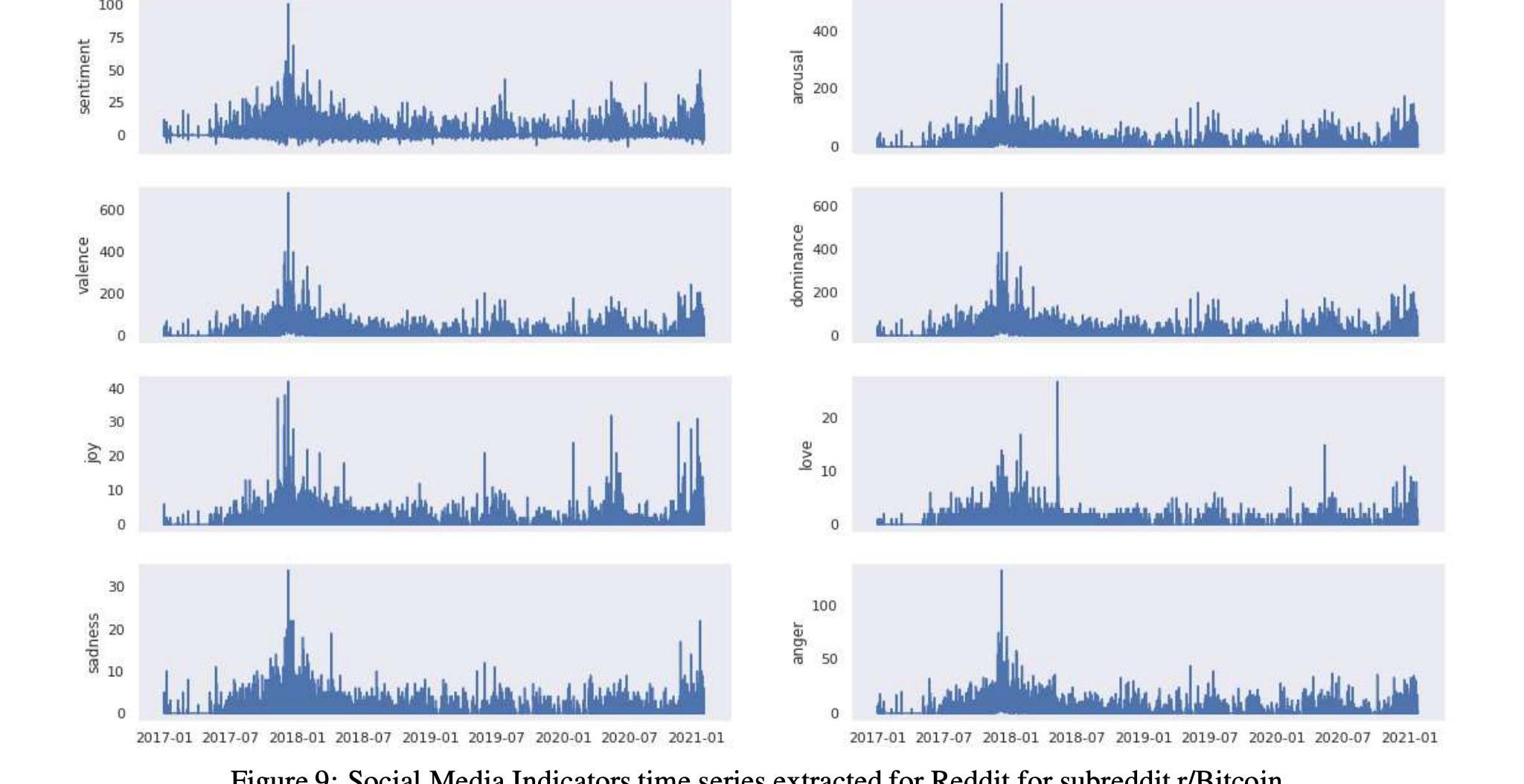
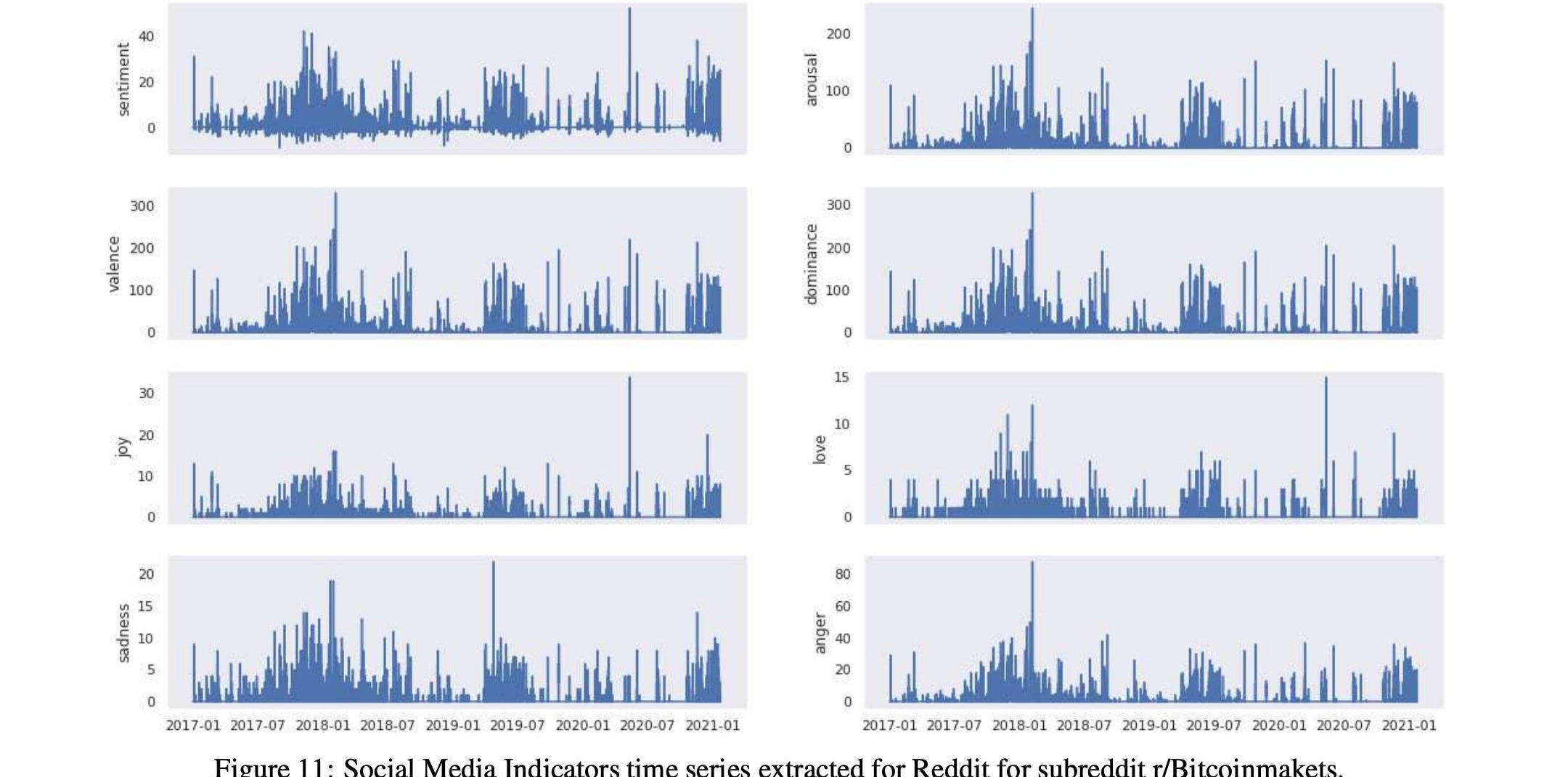
而表17和15以及图10和12显示了这两个以太坊子Reddits的统计数据和时间序列。
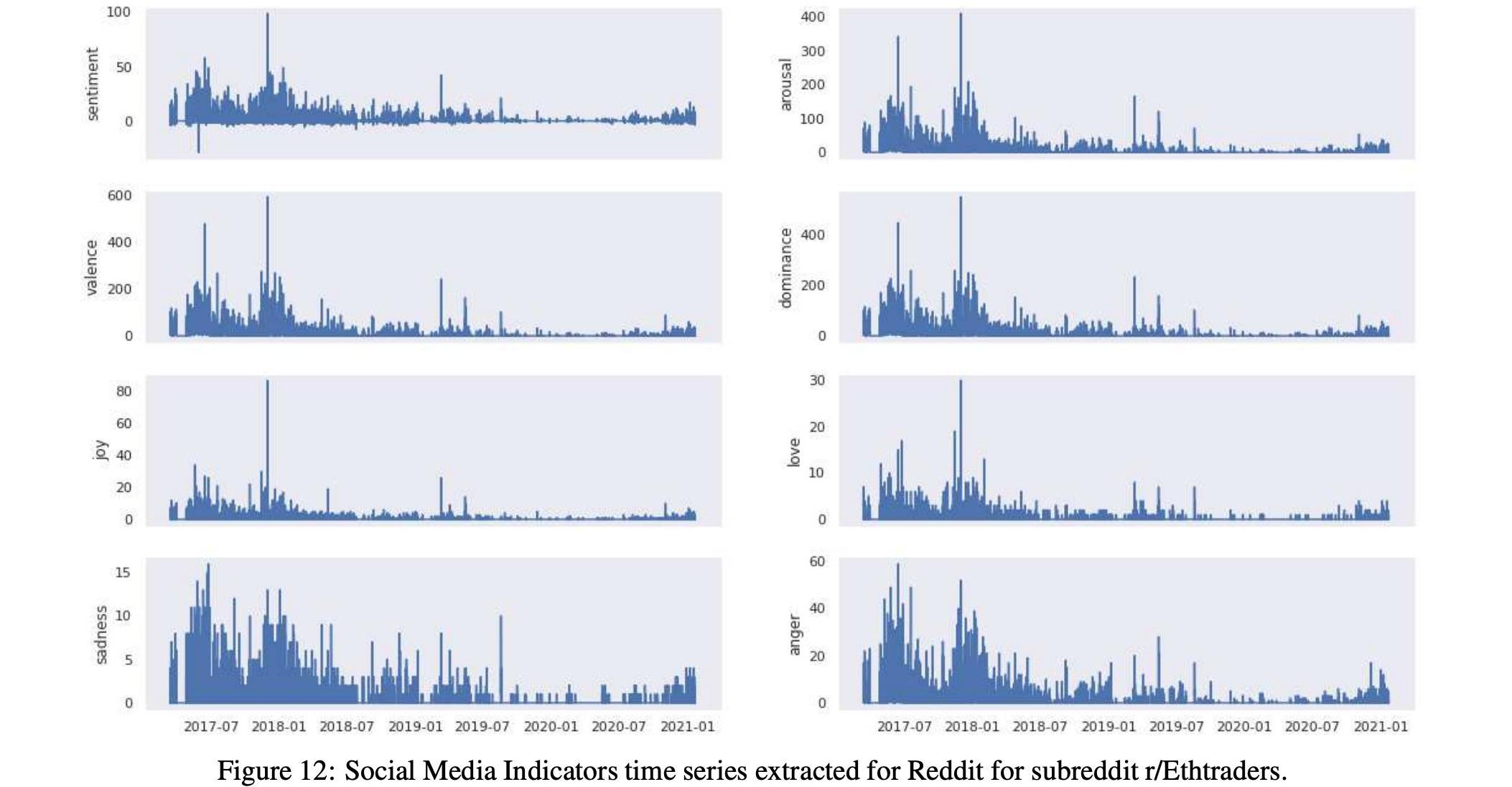
2.4价格变动分类
目标变量是一个二进制变量,下面列出了两个唯一的类。
上涨:这个类,标记为向上,编码为1,表示价格上涨的情况。
下跌:此类标记为向下并用0编码,表示价格下跌的情况。
图13显示了每小时和每日频率的类分布和数据集,突出显示了我们在每小时频率的情况下处理的是相当平衡的分类问题,在每日频率的情况下处理的是稍微不平衡的分类问题。
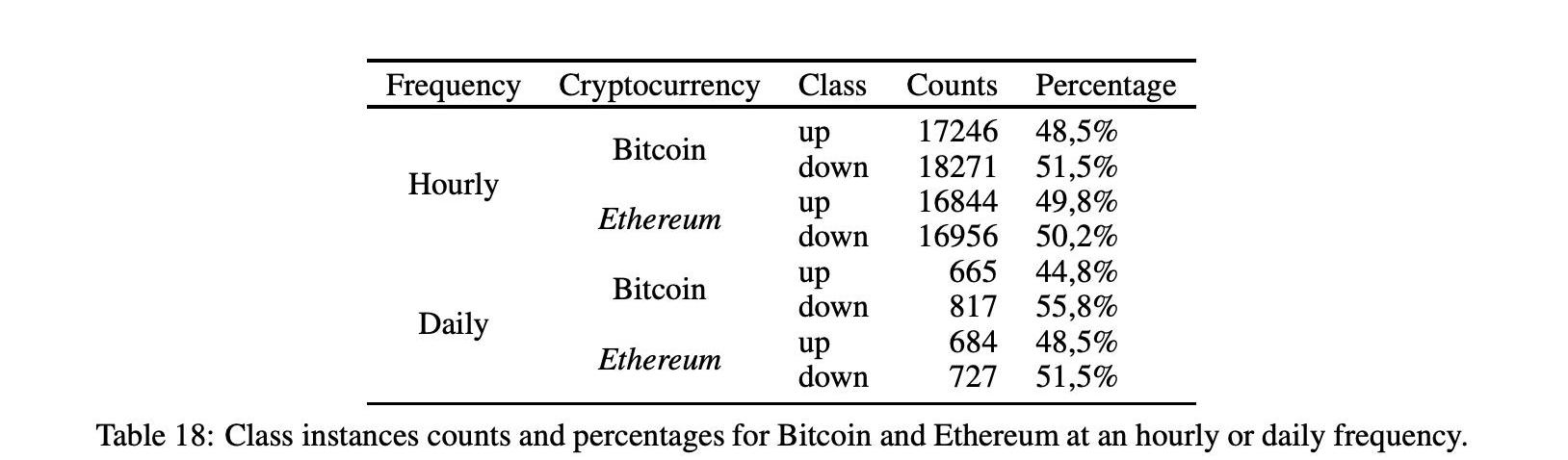
表18显示了上涨下跌实例的详细信息,比特币的实例分别为48%、5%和51.5%,以太坊的实例分别为49%、8%和50%、2%。对于每日频率,比特币为44%、8%和55.2%,以太坊为48%、5%和51%、5%。对于比特币的日频率,我们有一个稍微不平衡的分布向上类,在这种情况下,我们将考虑f1分数连同准确性,以评估模型的性能。
声音 | 推特CEO:推特正在“考虑”如何应用区块链技术:据coindesk报道,推特CEO Jack Dorsey今日向美国国会委员会表示,该社交媒体公司正在为其平台探索区块链解决方案。Dorsey表示,区块链具有很多未开发的潜力,特别是围绕分布式信任和分布式执行。推特目前没有在区块链上研究得那么深入,但Dorsey愿意了解应怎样把区块链应用到推特,该公司现在确实有员工在“考虑”此事。[2018/9/6]
2.5时间序列处理
由于我们使用的是有监督学习问题,我们准备我们的数据有一个向量的x输入和y输出与时间相关。在这种情况下,输入向量x称为回归量。x输入包括模型的预测值,即过去的一个或多个值,即所谓的滞后值。输入对应于前面章节中讨论的选定特征的值。目标变量y是二进制变量,可以是0或1。0实例表示价格向下跌。当时间t的收盘价与时间t+1的开盘价之差小于或等于0时,获得时间t的0实例。1实例表示价格向上,即价格上涨情况。当时间t的收盘价与下一时间步t+1的开盘价之差大于0时,得到1实例。我们考虑了两个时间序列模型:
受限:输入向量x仅包含技术指标。
无限制:输入向量x由技术、交易和社交媒体指标组成。
对于限制模型和非限制模型,我们对每个指标使用1个滞后值。这种区分的目的是确定和量化回归向量中添加的交易和社交媒体情绪指标是否会有效改善比特币和以太坊的价格变化分类。
3方法论
本节描述了我们分析中考虑的深度学习算法,然后讨论了超参数的微调。
3.1多层感知器
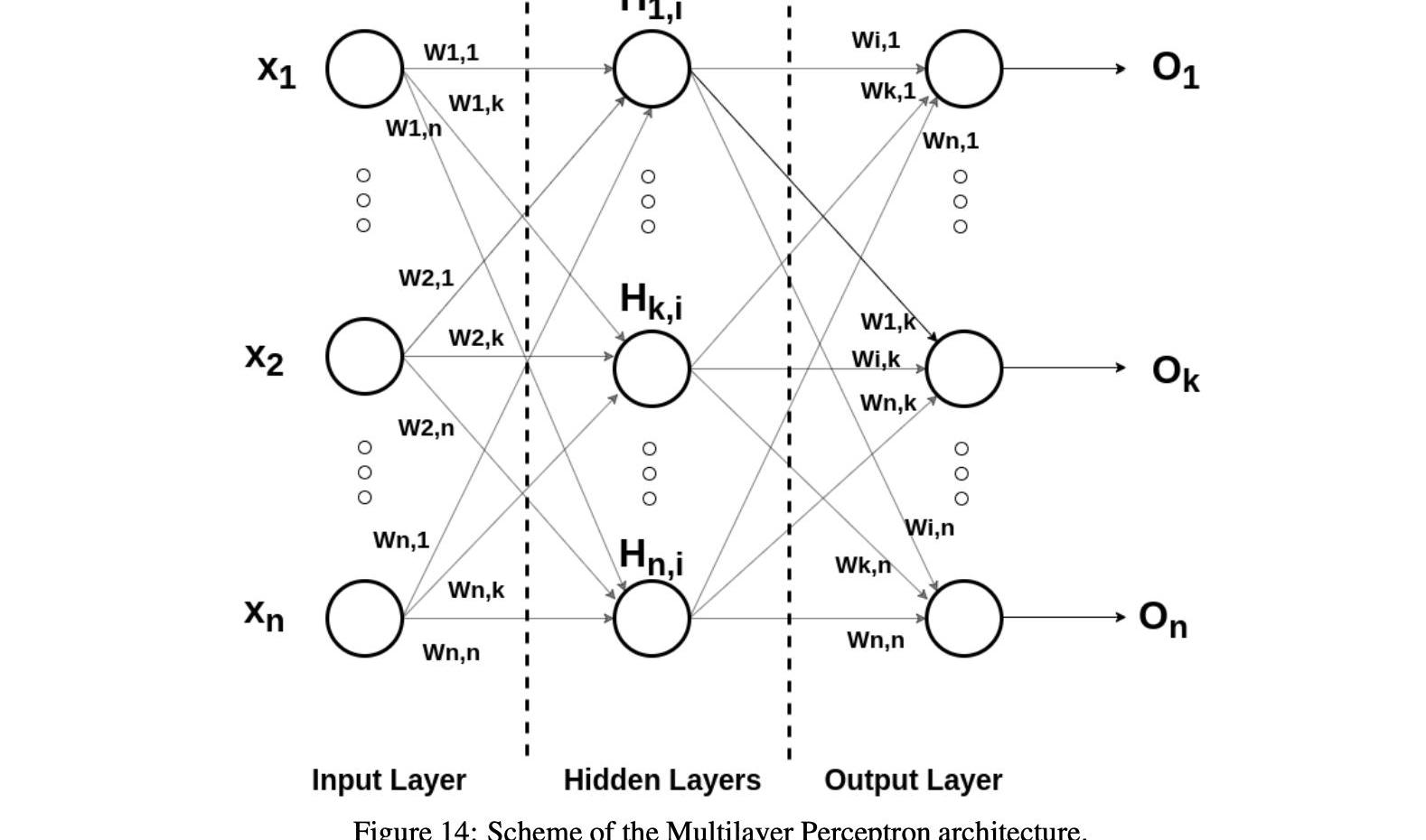
多层感知器是一类前馈人工神经网络,具有多层感知器和典型的激活函数的特点。
最常见的激活功能有:
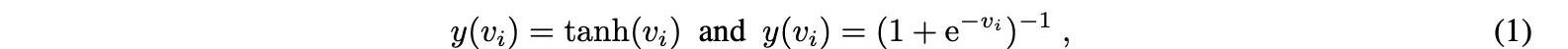
其中Vi是输入的加权向量。
MLP包含三个主要节点类别:输入层节点、隐藏层节点和输出层节点。除了输入节点外,神经网络的所有节点都是使用非线性激活函数的感知器。MLP不同于线性感知器,因为它具有多层结构和非线性激活函数。
一般来说,MLP神经网络对噪声有很强的抵抗能力,并且在缺失值时也能支持学习和推理。神经网络对映射函数没有很强的假设,很容易学习线性和非线性关系。可以指定任意数量的输入特征,为多维预测提供直接支持。可以指定任意数量的输出值,为多步甚至多变量预测提供直接支持。基于这些原因,MLP神经网络可能对时间序列预测特别有用。
在深度学习技术的最新发展中,整流线性单元是一种分段线性函数,经常被用来解决与sigmoid函数相关的数值问题。ReLU的例子是在-1和1之间变化的双曲正切函数,或者在0和1之间变化的logistic函数。这里第i个节点的输出是yi,输入连接的加权和是vi。
通过包含整流器和softmax函数,开发了替代激活函数。径向基函数包括更高级的激活函数。
由于MLPs是完全连接的架构,因此一层中的每个节点用特定的权重wi,j连接到下一层中的每个节点。神经网络的训练采用有监督的反向传播法和最优化方法。数据处理后,感知机通过调整连接权值进行学习,这取决于输出中相对于预期结果的误差量。感知器中的反向传播是最小均方算法的推广。
当第n个训练样本呈现给输入层时,输出节点j中的误差量为ej=dj?yj,其中d是预测值,y是感知器应生成的实际值。然后,反向传播方法调整节点权重以最小化等式提供的整个输出误差:
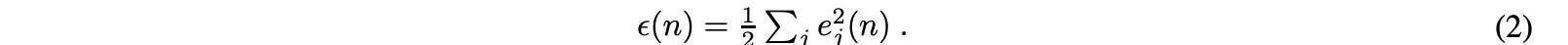
使用公式中的梯度下降法进一步计算每个节点权重的调整,其中yi是前一个神经元的输出,η是学习率:
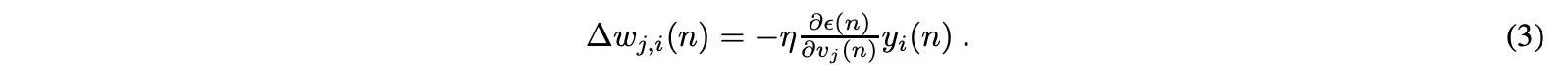
参数η通常被设置为权值收敛到响应和响应周围振荡之间的权衡。
感应局部场vj变化,可以计算其导数:
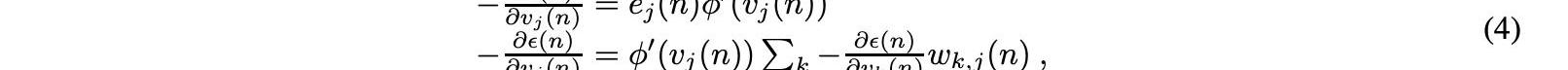
式中,φ′是上述激活函数的导数,激活函数本身不变。当修改隐藏节点的权重时,分析更为困难,但可以证明,相关的量是等式中所示的量。该算法表示激活函数的反向传播,如等式所示,取决于表示输出层的第k层的权重的调整,而该调整又取决于隐藏层权重的激活函数的导数。
3.2长短期记忆网络
长短期记忆网络是递归神经网络的一种特殊形式,能够捕捉数据序列中的长期依赖关系。RNN是一种具有特定拓扑结构的人工神经网络,专门用于识别不同类型数据序列中的模式:例如,自然语言、DNA序列、手写、单词序列或来自传感器和金融市场的数字时间序列数据流。经典的递归神经网络有一个显著的缺点,那就是它们不能处理长序列和捕捉长期的依赖关系。RNN只能用于具有短期内存依赖性的短序列。LSTM是用来解决长期记忆问题的,它是直接从RNN派生出来的,用来捕获长期的依赖关系。LSTM神经网络以单元为单位组织,通过应用一系列运算来执行输入序列变换。内部状态变量在从一个单元转发到下一个单元时由LSTM单元保留,并由所谓的操作门更新,如图16所示。所有三个门都有不同且独立的权值和偏差,因此网络可以了解要维持多少以前的输出和电流输入,以及有多少内部状态要传递给输出。这样的门控制有多少内部状态被传输到输出,并且与其他门的操作类似。LSTM单元包括:
雕爷:区块链将如何改变世界:在币圈近期比较火的陈伟星和朱啸虎的口水战中,雕爷被一些人当成了“导火索”。雕爷对此作出了回应,他对于区块链的态度十分中立,同时他也承认,自己在2014年就拥有比特币。雕爷在自己的公众号中阐明了自己的看法:区块链可以传递原本无法分割的价值,区块链创造价值必须依附于已经能够真实创造价值且可以被验证的商业场景。雕爷还称,现在有大量资金涌入区块链行业,一年后则会留下一些认真办事的人。所以现在是投身区块链行业的好时机,一年后也是。[2018/2/25]
1单元状态:这个状态带来整个序列的信息,并代表网络的内存。
2遗忘门:它过滤从以前的时间步中保留的相关信息。
3输入门:它决定从当前时间步添加哪些相关信息。
4输出门:它控制当前时间步的输出量。
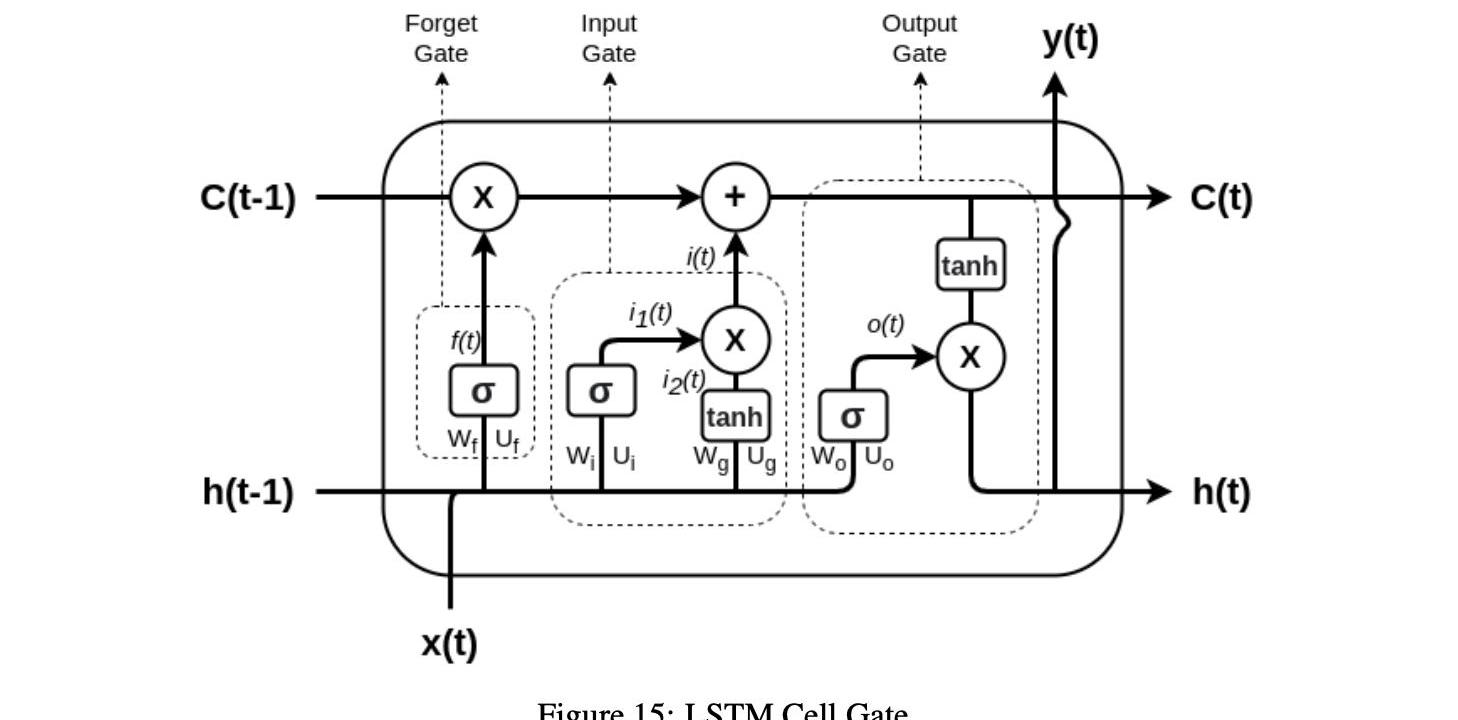
第一步是忘记门。这个门将过去的或滞后的值作为输入,并决定应该忘记多少过去的信息以及应该保存多少。先前隐藏状态的输入和当前输入通过sigmoid函数传输到输出门。当可以忘记该信息时,输出接近0,而当要保存该信息时,输出接近1,如下所示:
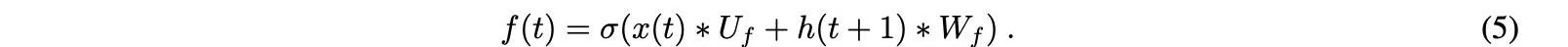
矩阵Wf和Uf分别包含输入连接和循环连接的权重。下标f可以表示忘记门。xt表示LSTM的输入向量,ht+1表示LSTM单元的隐藏状态向量或输出向量。
第二个门是输入门。在这个阶段,单元状态被更新。先前的隐藏状态和当前输入最初表示为sigmoid激活函数的输入。为了提高网络调谐,它还将隐藏状态和电流输入传递给tanh函数,以压缩?1和1之间的值。然后将tanh和sigmoid的输出逐元素相乘。等式6中的sigmoid输出确定了要从tanh输出中保留的重要信息:
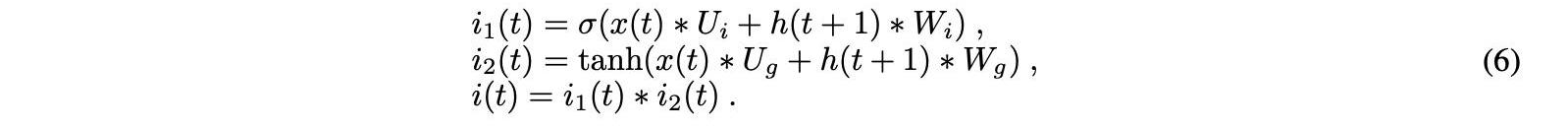
单元状态可以在输入门激活之后确定。接下来,将上一时间步的单元状态逐元素乘以遗忘门输出。这会导致在单元格状态下,当值与接近0的值相乘时,忽略值。输入门输出按元素添加到单元状态。方程7中的新单元状态是输出:
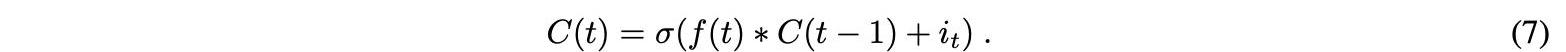
最后一个门是输出门,它指定下一个隐藏状态的值,该值包含一定量的先前输入信息。在这里,当前输入和先前的隐藏状态相加并转发到sigmoid函数。然后新的细胞状态被转移到tanh函数。最后,将tanh输出与sigmoid输出相乘,以确定隐藏状态可以携带哪些信息。输出是一个隐藏的新状态。新的单元状态和新的隐藏状态然后通过等式8移动到下一阶段:
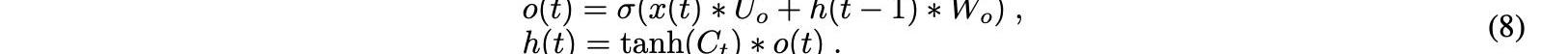
为了进行这一分析,我们使用Keras框架进行深度学习。我们的模型由一个堆叠的LSTM层和一个密集连接的输出层和一个神经元组成。
3.3注意机制神经网络
注意函数是深度学习算法的一个重要方面,它是编码器-译码器范式的扩展,旨在提高长输入序列的输出。图16显示了AMNN背后的关键思想,即允许解码器在解码期间有选择地访问编码器信息。这是通过为每个解码器步骤创建一个新的上下文向量来实现的,根据之前的隐藏状态以及所有编码器的隐藏状态来计算它,并为它们分配可训练的权重。通过这种方式,注意力技巧赋予输入序列不同的优先级,并更多地关注最重要的输入。
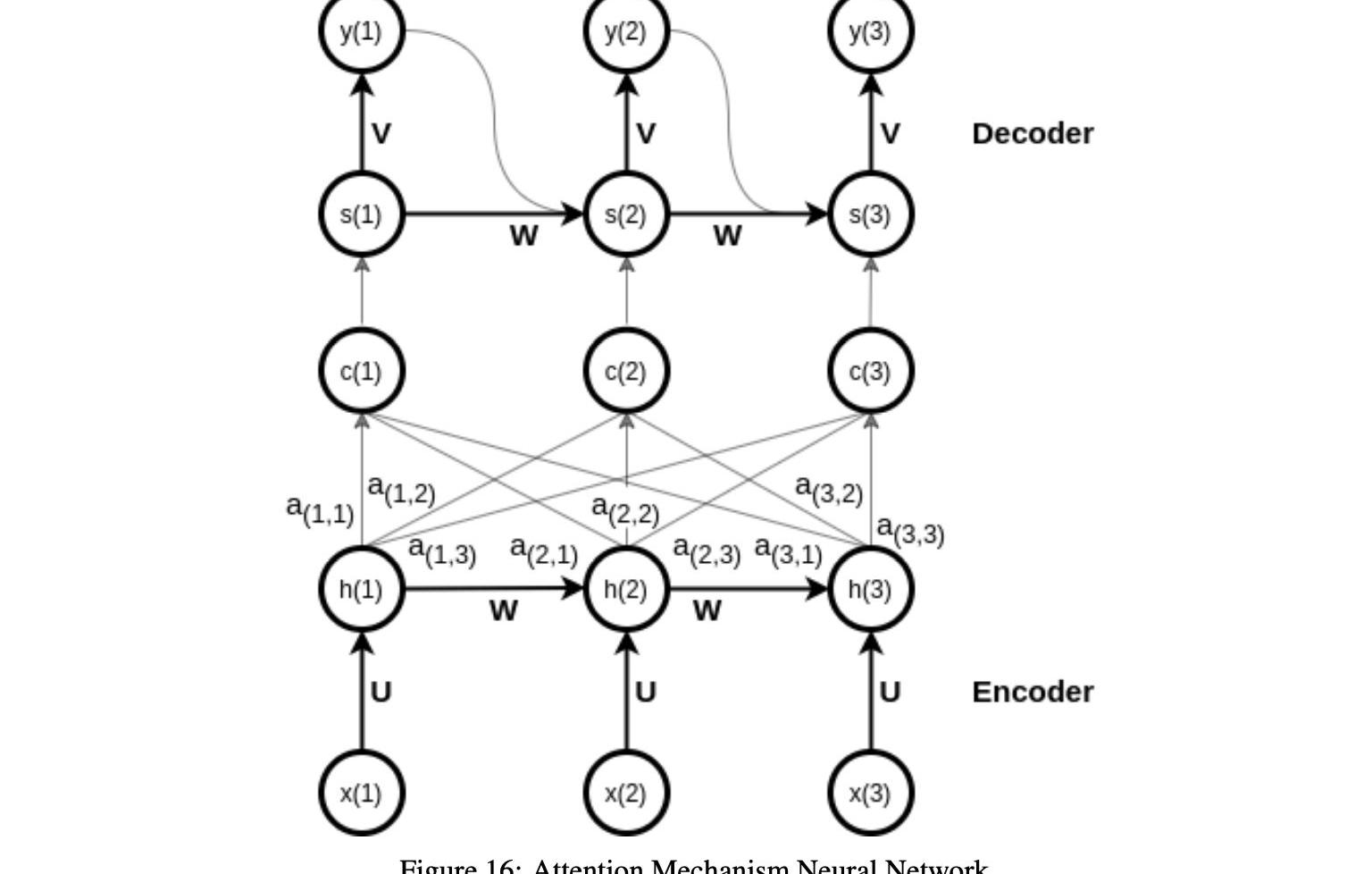
编码器操作与编码器-解码器混合操作本身非常相似。每个输入序列的表示在每个时间步确定,作为前一时间步的隐藏状态和当前输入的函数。
最终隐藏状态包括来自先前隐藏表示和先前输入的所有编码信息。
注意机制和编解码器模型之间的关键区别在于,对于每个解码器步骤t,计算一个新的背景向量c。我们如下进行以测量时间步长t的上下文向量c。首先,对于编码器的时间步长j和解码器的时间步长t的每个组合,使用等式中的加权和来计算所谓的对齐分数e:
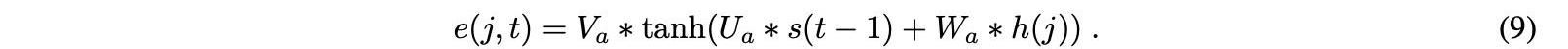
Wa、Ua和Va是这个公式中的学习权重,它们被称为注意权重。Wa权重链接到编码器的隐藏状态,Ua权重链接到解码器的隐藏状态,Va权重确定计算对齐分数的函数。分数e在编码器j的时间段上使用softmax函数在每个时间步t处归一化,获得如下注意权重α:
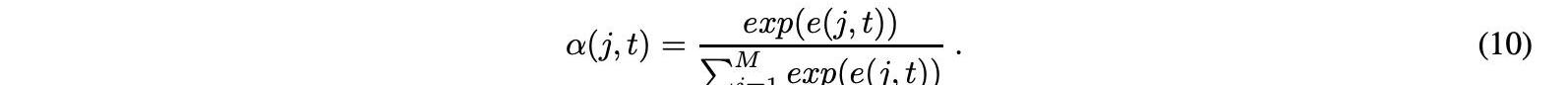
时间j处的输入的重要性由用于解码时间t的输出的注意权重α表示。根据作为编码器的所有隐藏值的加权和的注意权重来估计上下文向量c,如下所示:
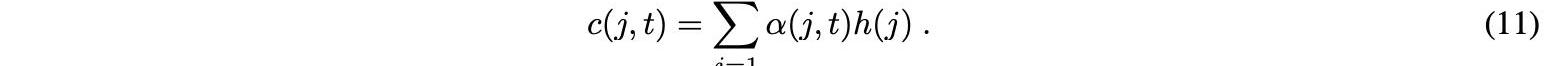
根据这种方法,所谓的注意功能是由上下文数据向量触发的,对最重要的输入进行加权。
上下文向量c现在被转发到解码器以计算下一个可能输出的概率分布。此解码操作涉及输入中存在的所有时间步长。然后根据循环单位函数计算当前隐藏状态s,将上下文向量c、隐藏状态s和输出y?作为输入,根据以下等式:
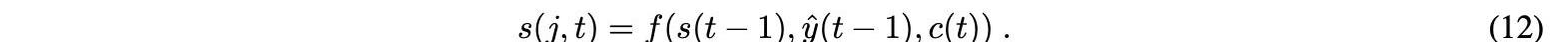
利用该函数,模型可以识别输入序列不同部分与输出序列相应部分之间的关系。softmax函数用于在每个时刻t计算处于加权隐藏状态的解码器的输出:
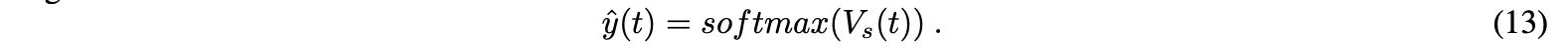
对于LSTM,由于注意权值的存在,注意机制在长输入序列下提供了更好的结果。
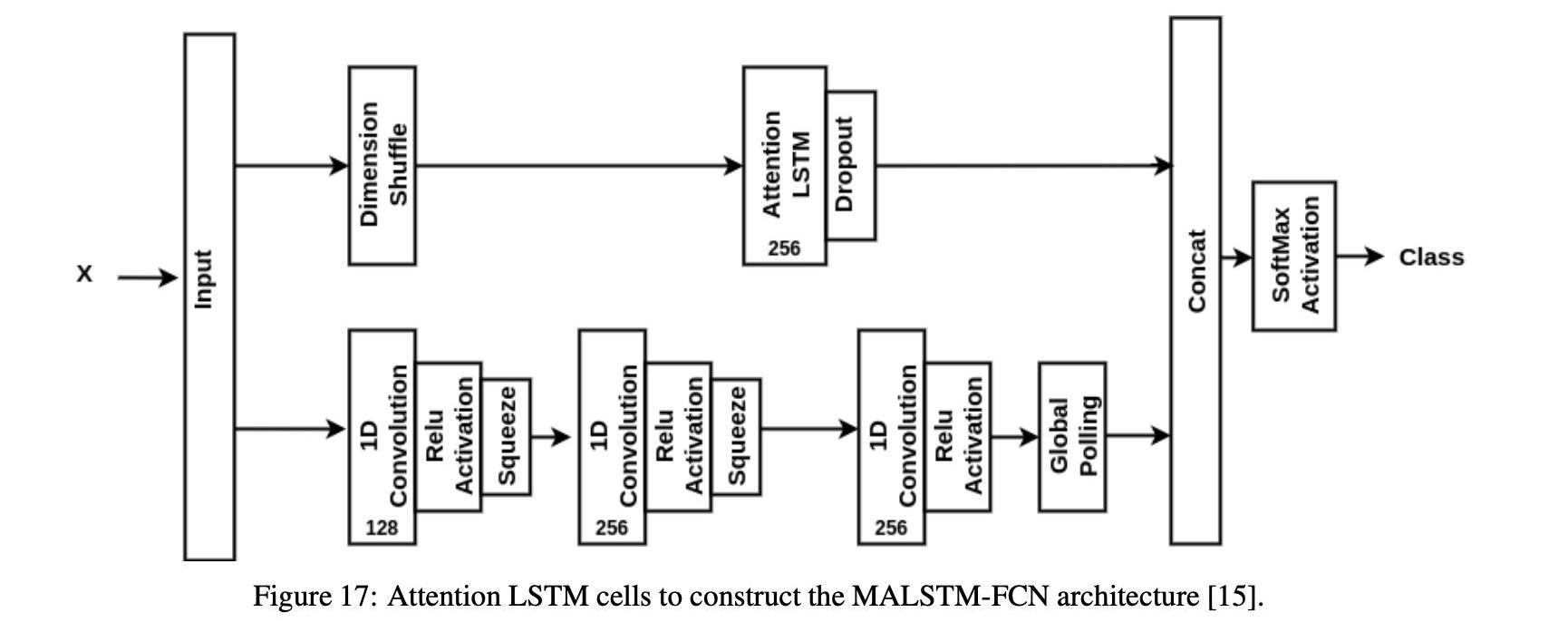
在这项研究中,我们特别使用了Fazle等人提出的具有完全卷积网络的多元注意LSTM。图17显示了MALSTM-FCN的体系结构,包括每层的神经元数量。输入序列与完全卷积层和注意LSTM层并行,并通过用于二进制分类的softmax激活函数连接和传递到输出层。全卷积块包含三个分别由128、256和256个神经元组成的时间卷积块,用作特征抽取器。在级联之前,每个卷积层通过批量归一化来完成。维洗牌变换输入数据的时间维,使得LSTM一次获得每个变量的全局时间信息。因此,对于时间序列分类问题,维数洗牌操作减少了训练和推理的计算时间,同时又不损失精度。
3.4卷积神经网络
卷积神经网络是一类特殊的神经网络,最常用于图像处理、图像分类、自然语言处理和金融时间序列分析等深度学习应用。
CNN架构中最关键的部分是卷积层。这层执行一个称为卷积的数学运算。在这种情况下,卷积是一种线性运算,它涉及输入数据矩阵和二维权值数组之间的乘法。这些网络在至少一层中使用卷积运算。
卷积神经网络具有与传统神经网络相似的结构,包括输入输出层和多个隐层。CNN的主要特征是其隐藏层通常由执行上述操作的卷积层组成。图18描述了用于时间序列分析的CNNs的一般架构。我们使用一个一维卷积层,而不是通常的二维卷积层典型的图像处理任务。然后用轮询层对第一层进行归一化,然后将其展平,以便输出层可以在每个步骤t处处理整个时间序列。在这种情况下,许多一维卷积层可以组合在深度学习网络中。
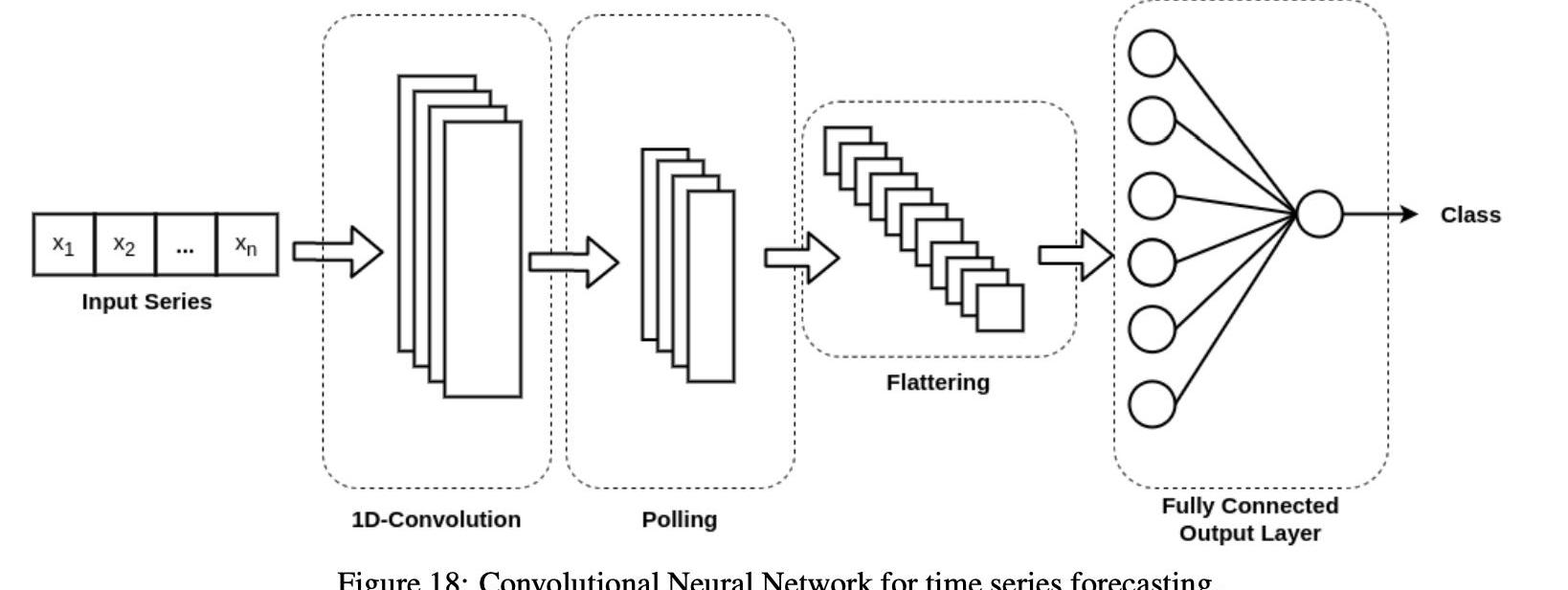
对于CNN的实现,我们使用Keras框架进行深入学习。我们的模型由两个或多个堆叠的一维CNN层组成,一个密接层有N个神经元用于轮询,一个密接层有N个神经元用于平坦化,最后一个密接输出层有一个神经元。
3.5超参数调整
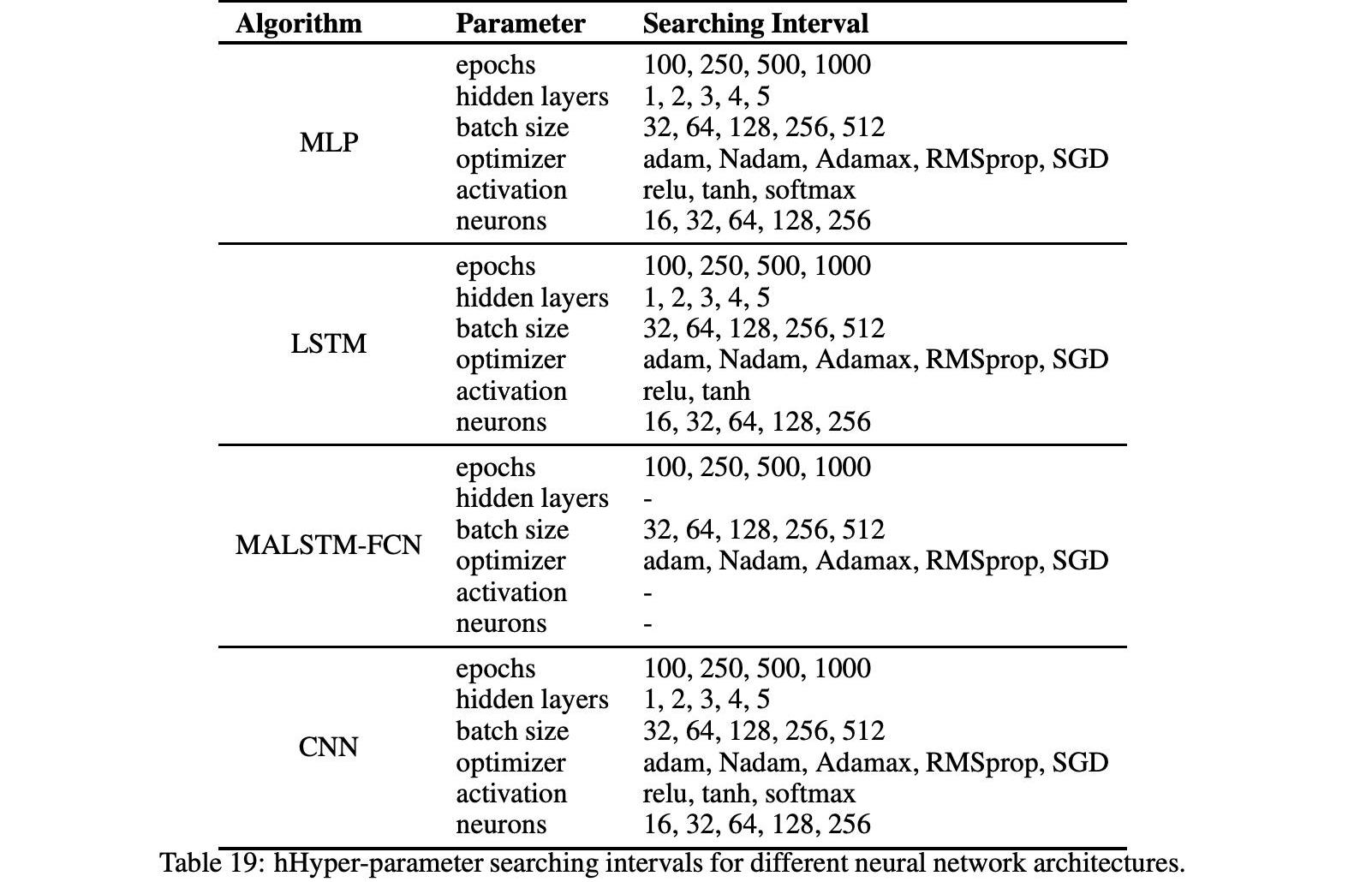
超参数调整是对给定算法的超参数进行优化的一种方法。它用于确定超参数的最佳配置,以使算法获得最佳性能,并根据特定的预测误差进行评估。对于每个算法,选择要优化的超参数,并为每个超参数定义适当的搜索间隔,包括所有要测试的值。然后将该算法与第一个选定的超参数配置匹配到数据集的特定部分。拟合模型在训练阶段以前没有使用过的部分数据上进行测试。此测试程序返回所选预测误差的特定值。
通过网格搜索程序的优化程序在测试了所有可能的超参数值组合后结束。因此,选择在所选预测误差方面产生最佳性能的超参数配置作为优化配置。表19显示了每个实现算法的超参数搜索间隔。由于MALSTM-FCN是一种特定于深层神经网络的体系结构,层的数量、每层的神经元数以及每层的激活函数已经预先指定。
为了确保超参数优化过程的鲁棒性,我们使用模型验证技术来评估给定模型所获得的性能如何推广到一个独立的数据集。此验证技术涉及将数据样本划分为训练集、验证集和测试集。在我们的分析中,我们使用37.8%的袋外样本和10000次迭代来实现Boostrap方法,以验证最终的超参数。
4实验证据
在本节中,我们报告并讨论分析的主要结果。特别地,我们讨论了限制模型和非限制模型的结果。这些结果是根据标准的分类错误度量来评估的:准确度、f1分数、准确度和召回率。
4.1受限模型的超参数
我们在这里简要讨论了3.5节中提到的四种深度学习算法的超参数的微调,考虑到每小时的频率。表20显示了在分类误差度量方面使用网格搜索技术对不同神经网络模型获得的最佳结果。表20列出了MALSTM-FNC和MLP模型的最佳识别参数和相关结果。
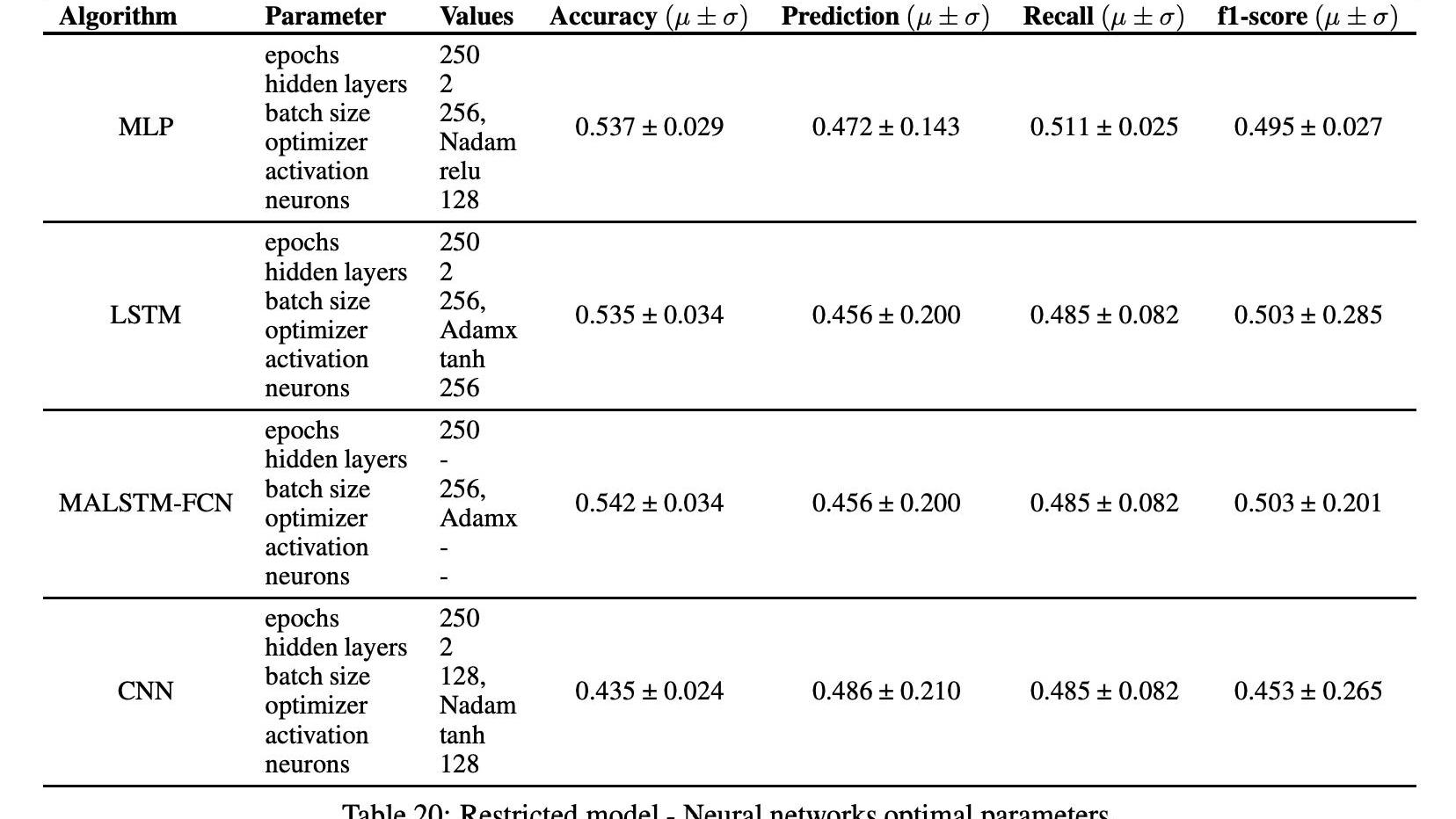
获得最佳精确度的神经网络是MALSTM-FNC,平均精确度为53.7%,标准偏差为2.9%。在实施的机器学习模型中,获得最佳f1分数的是MALSTM-FNC,平均准确率为54%,标准偏差为2.01%。
4.2无限制模型的超参数
表21显示了神经网络模型通过网格搜索技术获得的关于分类误差度量的最佳结果。CNN和LSTM模型的最佳识别参数和相关结果见表21。
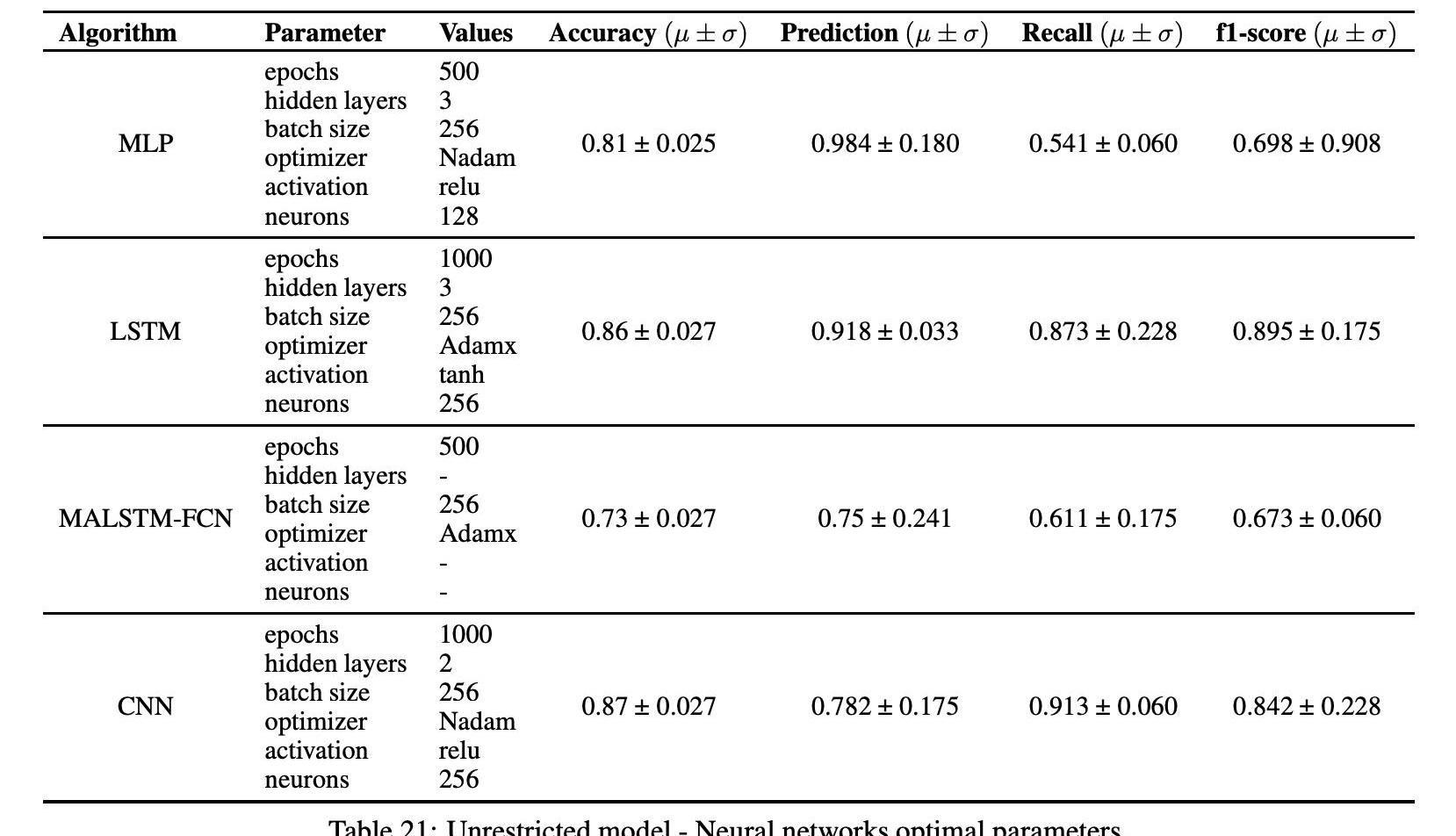
对于无限制模型的结果表明,在模型中加入交易和社交媒体指标可以有效地提高平均准确度,即预测误差。对于所有实现的算法,这个结果都是一致的,这允许我们排除这个结果是统计波动,或者它可能是实现的特定分类算法的人工制品。利用CNN模型得到了无约束模型的最佳结果,平均准确率为87%,标准差为2.7%。
4.3结果和讨论
表22显示了使用四种深度学习算法进行时频价格变动分类任务的结果。此表显示了受限和非受限模型的结果。首先,可以注意到,对于所有四种深度学习算法,无限制模型在精确度、查全率、召回率和F1分数方面都优于限制模型。准确率范围从限制MLP的51%到CNNs和LSTM的84%。
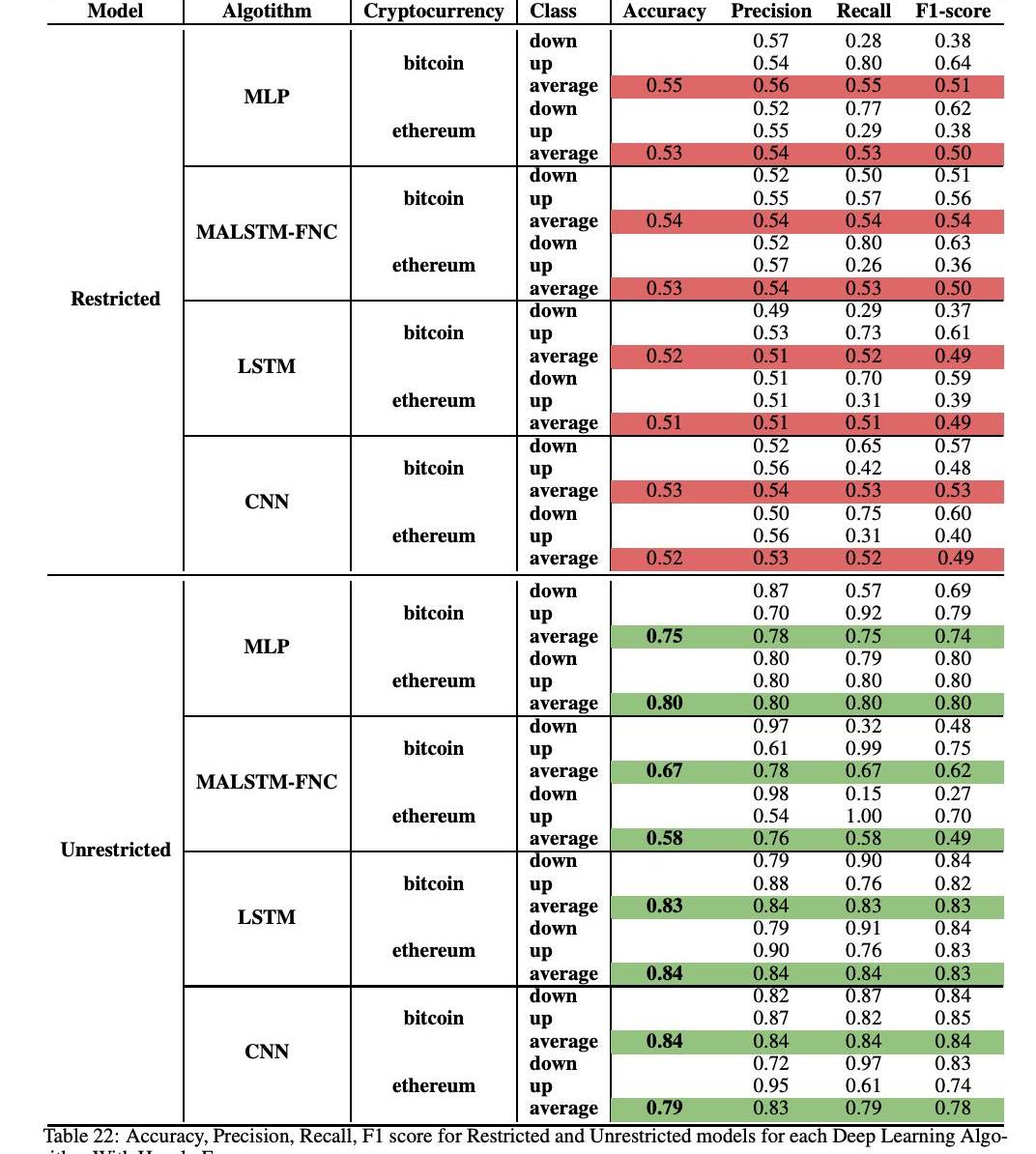
事实上,这四个分类器的结果是一致的,进一步证实了这不是由于统计波动,而是由于较高的预测无限制模型。对于比特币,最高的性能是通过CNN架构获得的,而对于以太坊则是通过LSTM获得的。
我们还进一步探讨了按小时频率的无限制模型的分类,考虑了两个子模型:一个子模型包括技术和社交指标,另一个子模型包括所有指标。这样,就可以理清社会和交易指标对模型性能的影响。我们对两个无限制子模块的准确度、预测、回忆和F1得分的分布进行了统计t检验,发现增加社会指标并不能显著改善无限制模型。因此,在表22中,我们省略了仅包括社会和技术指标的无限制模型。
表23显示了四种深度学习算法对日频率价格变动分类的结果。此表显示了受限和非受限模型的结果。将无限制模型进一步划分为技术-社会和技术-社会-交易子模型,以更好地分别突出社会和交易指标对模型的贡献。
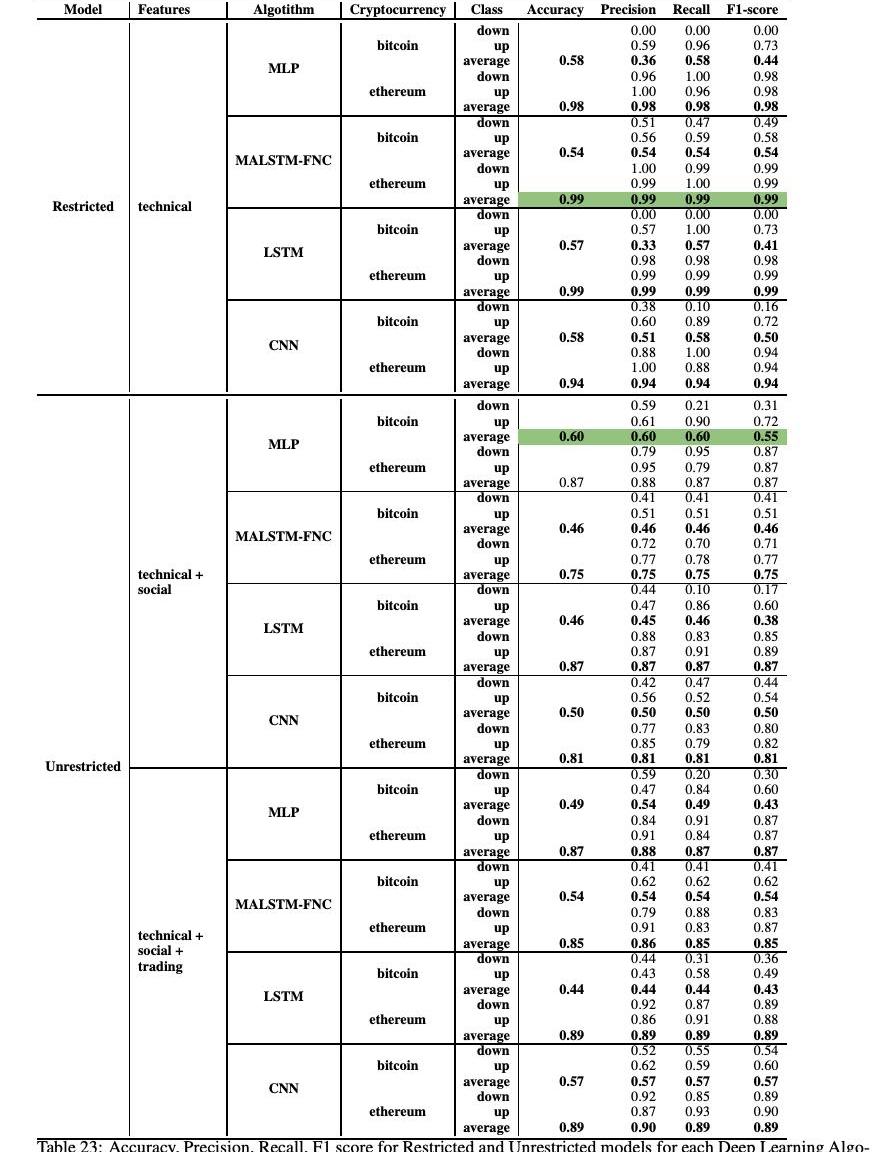
MALSTM-CNF使用仅由技术指标组成的受限模型,以99%的准确率实现了以太坊的最佳分类性能。对于比特币而言,MLP的F1分数为55%,准确率为60%,而不受限制的模型只有社交媒体指标和技术指标。对于日频率分类,我们可以看到,在一般技术指标单独表现更好的分类第二天的价格走势。我们向模型中添加的指标越多,性能下降的幅度就越大。另一个普遍的结果是,以太坊每日价格变动分类的准确性、精确性、召回率和F1分数远远好于比特币。日分类的结果与其他研究一致,小时和日分类在考虑小时无限制模型时有显著改进。社交媒体指标在比特币案件的日常频率上尤其重要。这一结果与最近关于社交媒体情绪对加密货币市场影响的结果一致:社交媒体对市场的影响表现出很长的滞后性,这种滞后性不是每小时捕捉到的,也不是每小时相关的。
5有效性的威胁
在本节中,我们将讨论对我们的分析有效性的潜在限制和威胁。首先,我们的分析侧重于以太坊和比特币:这可能会对外部有效性构成威胁,因为对不同的加密货币进行分析可能会导致不同的结果。
第二,对内部效度的威胁与影响结果的混杂因素有关。基于经验证据,我们假设技术、交易和社会指标在我们的模型中是详尽无遗的。尽管如此,本研究可能忽略了其他可能影响价格变动的因素。
最后,结构效度的威胁集中在观察结果如何准确地描述感兴趣的现象上。价格变动的检测和分类是基于描述整个现象的客观数据。一般来说,技术指标和交易指标是以客观数据为基础的,通常是可靠的。社交媒体指标是基于通过使用公开数据集训练的深度学习算法获得的实验测量:这些数据集可能带有内在偏见,而这些偏见又会转化为情感和情绪的分类错误。
6结论
在最近的文献中,人们曾多次尝试对主要加密货币的价格或其他市场指标的不稳定行为进行建模和预测。尽管许多研究小组致力于这一目标,密码货币市场的分析仍然是最有争议和难以捉摸的任务之一。有几个方面使解决这个问题变得如此复杂。例如,由于其相对年轻,加密货币市场是非常活跃和快节奏的。新加密货币的出现是一个常规事件,导致市场本身的组成发生意外和频繁的变化。此外,加密货币的高价格波动性及其“虚拟”性质同时也是投资者和交易员的福音,也是任何严肃的理论和实证模型的诅咒,具有巨大的实际意义。对这样一个年轻市场的研究,其价格行为在很大程度上还没有被探索,不仅在科学领域,而且对投资者和加密市场格局中的主要参与者和利益相关者都有着根本性的影响。
在本文中,我们旨在评估在“经典”技术变量中添加社会和交易指标是否会导致加密货币价格变化分类的实际改进。这一目标是实现和基准广泛的深度学习技术,如多层感知器,多元注意长期短期记忆完全卷积网络,卷积神经网络和长期短期记忆神经网络。我们在分析中考虑了比特币和以太坊这两种主要的加密货币,并分析了两种模型:一种是仅考虑技术指标的受限模型,另一种是包括社会和交易指标的非受限模型。
在限制性分析中,就准确度、精确度、召回率和f1分数而言,获得最佳性能的模型是MALSTM-FCN,比特币的f1平均分数为54%,以太坊的CNN为小时频率。在不受限制的情况下,LSTM神经网络对比特币和以太坊的平均准确率分别为83%和84%。对于无限制模型的小时频率分类,最重要的发现是,在模型中加入交易和社会指标可以有效地提高平均准确度、精确度、召回率和f1分数。我们已经证实,这一发现不是统计波动的结果,因为所有实施的模型都取得了相同的成果。出于同样的原因,我们可以排除结果依赖于特定的实现算法。最后,对于日常分类,当使用仅包含技术指标的受限模型时,MALSTM-CNFforEthereum以99%的准确率实现了最佳分类性能。对于比特币而言,MLP的f1分数为55%,准确率为60%,无限制模型包括社交媒体指标和技术指标,在这种情况下,我们考虑比特币的f1分数和准确率,因为第3.4节中描述了略微不平衡的类别分布。对于日频率分类,我们可以看到,在一般技术指标单独表现更好的分类第二天的价格走势。我们向模型中添加的指标越多,性能下降的幅度就越大。
另一个普遍的结果是,以太坊每日价格变动分类的准确性、精确性、召回率和f1分数远远好于比特币。我们的结果表明,通过对深度学习体系结构的具体设计和微调,可以实现加密货币价格变化分类的高性能。
加密货币
币价
文章作者:币友_Anthony
我要纠错
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。
金色财经>区块链>如何准确预测加密货币价格?这篇内容了解下
过去一年来,DeFi迎来飞速发展。为应对我们在去年10月发布的文章中提到的变化,我们已经决定对关键的架构限制和问题动手.
本文由NewBloc原创,授权金色财经首发。本文作者为NewBloc策略分析师Barry,5年外汇黄金市场交易经历.
据官方消息,公链项目Taraxa将于2021年3月12日上午10点在证券代币发行和资产服务平台Tokensoft上进行代币TARA公募.
据TheBlock3月4日报道,总部位于德国科隆的经纪商Nextmarkets完成3000万美元B轮融资,总部位于马耳他的加密和区块链投资集团CryptologyAssetGroup领投.
?世界第一支比特币交易所交易基金(ETF)在发行的第一周就取得了巨大的成功。Glassnode的数据表明,该基金发行公司Purpose已经持有了超过10,000个比特币,截止发稿时持有比特币10.
摘要: 高盛正重新启动加密交易柜台,这是比特币的又一个看涨信号。该公司没有透露该交易柜台是否也将交易以太坊.