〇、题记
到底是“左右逢源”还是“举步维艰”,让子弹飞一会儿吧。所谓技术壁垒也许就是如何更清晰有效的描述需求了,但也很难形成技术壁垒。至于专利,软件著作权保护的是制作软件这个技术本身,而非你使用软件时的姿势,所以我想单独的prompt应该也不会形成专利,但是作为你某个技术的一部分,还是有可能的。LLM现阶段的表现是“懂开车的人才能开车”,所以需要更多更懂某个业务,更熟练使用LLM工具的人。这篇文章的目标:讨论在当前GPT-4如此强大的技术冲击下,普通NLP算法工程师该何去何从。本文章主要用来引发思考+讨论,如果您是NLP算法工程师,有什么新的观点或者Comment,可以加微信Alphatue
首先说下结论:GPT-4非常强大,但是我们认为,还没有到彻底取代NLP算法工程师工作的地步,依然有很多能做的方向。本文分为以下几部分:
一、GPT-4厉害在哪里?
二、GPT-4存在的问题?
三、NLP工程师可以努力的方向
四、何去何从?
五、申请Prompt专利?我们会不会失业?
一、GPT-4厉害在哪里?
1.更可靠了为什么?详情可见OpenAI的GPT-4TechnicalReport具体意思是,和以前的GPT-3.5模型相比,GPT-4大大减少了胡说八道的情况。
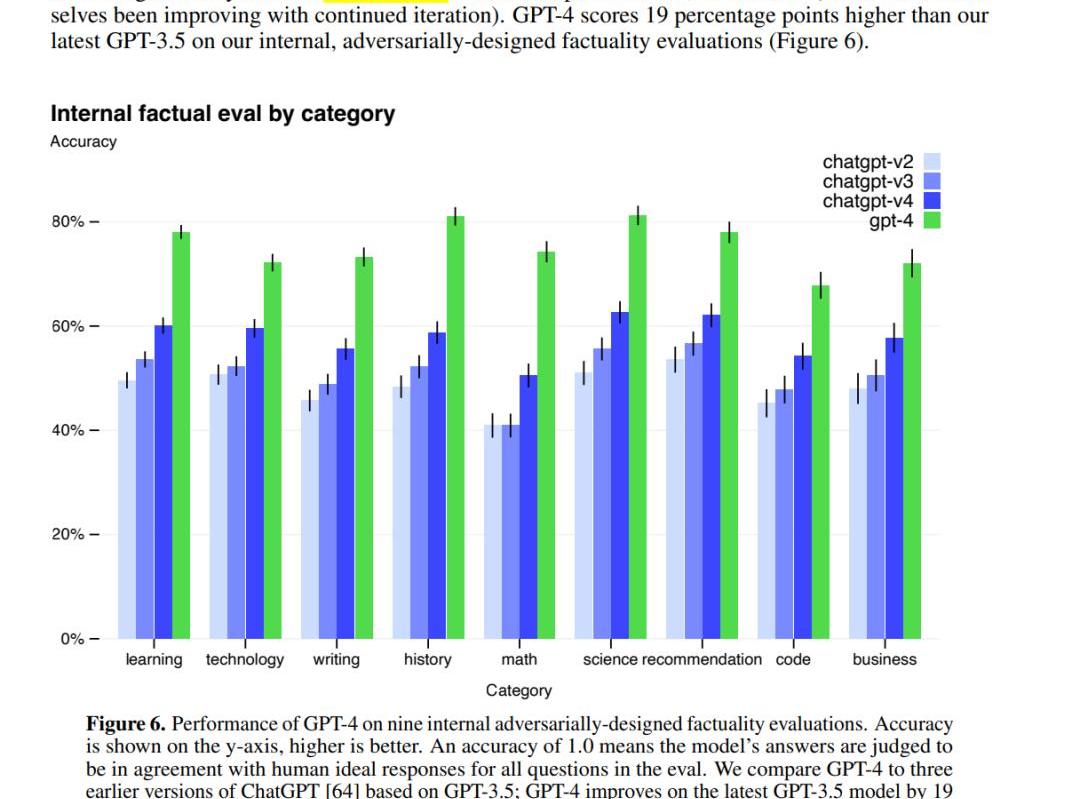
性能更好:比GPT-3.5又提升了一大截
Web3应用程序Kresus推出加密和NFT钱包:金色财经报道,Web3应用程序Kresus在iOS应用商店上线加密和NFT钱包SuperApp Kresus。每个Kresus用户将获得Kresus Web3 ID,可通过信用卡或Apple pay购买加密货币。
此前3月报道,Web3应用程序Kresus筹集到2500万美元A轮融资,LibertyCity Ventures领投。[2023/5/12 14:59:34]
具体表现在哪?根据论文里的例子,我们发现GPT-4在技术上有几个进步:
第一,多模态处理能力:GPT-4可以接受包含文本和图片的输入,并生成包括自然语言和代码在内的文本输出。这使得它在处理文档、图表或屏幕截图等任务时表现出色。第二,更好的性能和表现:相比前代GPT-3.5,在处理复杂任务时表现更为出色,在各大面向人类的考试中展示出了更高的准确性、可靠性、创造力和理解能力。第三,Test-TimeTechniques扩展能力:GPT-4使用了Test-TimeTechniques如few-shot和chain-of-thoughtprompting进一步扩展了其能力,使其能够更好地处理新领域和任务。第四,安全性优化:GPT-4重视安全性,生成回复的正确性得到了重点优化。它还进行了对抗性真实性评估,以避免潜在的安全隐患。第五,开源框架支持:OpenAI开源了用于评价大语言模型的开源框架OpenAIEvals,可以帮助研究人员和开发者评估他们的模型,并提供更好的指导。第六,模型训练和监控:OpenAI强调对模型进行评估和监控的重要性,以避免潜在的安全隐患。GPT-4也已被应用在了OpenAI内部,例如内容生成、销售和编程,并在模型训练的第二阶段负责输出评估、对齐工作。这里我们也抛一个问题:(究竟如何定义“模型的性能?”模型越来越难评估了,比如说,市场认为的某些某些不如chatgpt,但是也有人测试觉得更好,是怎么定量的评估呢?)3.Reverseinversescalingprize:一些随着模型变大性能下降的任务,在GPT-4上不再出现类似现象如何理解reverseinversescalingprize?通过阅读论文原文,InverseScalingPrize提出的几个任务,模型性能会随着scale的扩大而下降,但是我们发现GPT-4扭转了这一趋势。也就是说,GPT-4scale扩大,性能也不会下降。见下图:
DAS与WePiggy达成战略合作,将共同探索Web3.0和DeFi领域:8月30日,去中心化账户系统DAS与DeFi借贷协议WePiggy达成战略合作,共同探索“Web3.0+DeFi”领域,在Web3.0领域实现更便捷的跨链DID应用场景和更友好的跨链借贷体验,实现互利共赢。
DAS提供了一个跨链去中心化账户系统,通过集成DASAPI,WePiggy可以将网站上不同链的冗长地址替换为全球唯一且易于阅读的DAS帐户名称。[2021/8/31 22:48:18]
能够用图像做prompt:增加图像信息能进一步提升性能啥是BLIP2?论文:https://arxiv.org/pdf/2301.12597.pdf
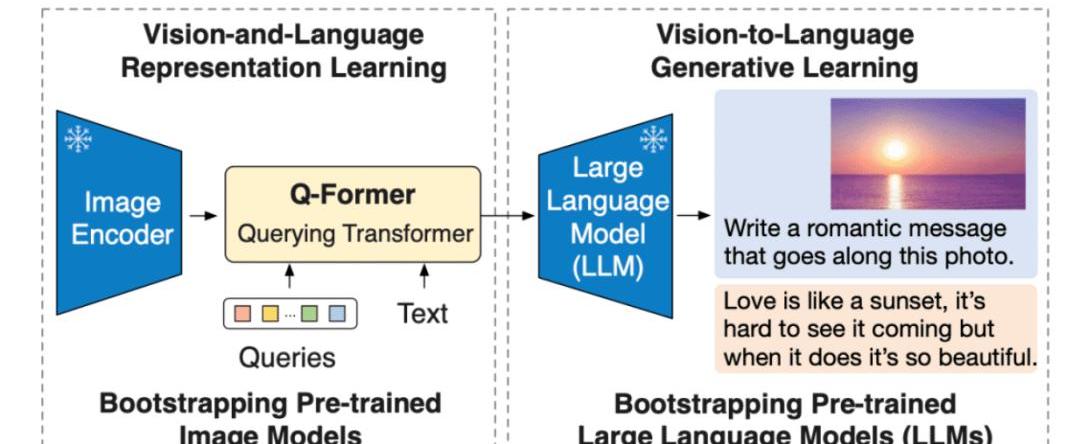
Salesforce研究院的BLIP-2模型,是一种视觉语言模型,可以用于图像字幕生成、有提示图像字幕生成、视觉问答及基于聊天的提示等多种应用场景。BLIP-2通过引入一种新的视觉语言预训练范式来解决端到端视觉语言预训练的高成本问题,并实现了在多个视觉语言任务上最先进的结果,同时减少了训练参数量和预训练成本。
二、GPT-4存在的问题
1.不开源
由于GPT-4完全不公布任何技术细节,所以为什么它有如此强大的能力,我们只能猜,想要研究它变得困难重重。
面向Web3.0的DAO操作系统Nutbox完成种子轮股权融资:据官方消息,面向Web3.0的DAO操作系统Nutbox宣布完成种子轮融资,本轮投资由WaterdripCapital领投,BML跟投。
Nutbox是一站式跨链质押经济和DAO平台,同时是内置“社交+DeFi”结合的一个多元化项目。目前Nutbox支持kusama网络的平行链插槽拍卖模块已经上线。Nutbox创始人尹国梓是WhereIN社区发起人,Steem超级节点代表。[2021/7/6 0:30:15]
2.数据安全
ChatGPT的火爆让大家突然忘了曾经非常看重的数据安全问题,preview版是有可能会参与下次迭代的;而商用API即使强调不会用于模型训练,敏感业务数据你敢用吗?
3.资源消耗大
即使是GPT-3也有175Billion参数,所有的训练/推理都是极其消耗资源的,从GPT-4的价格上涨了50%来看,我们认为GPT-4的推理消耗资源也上升了约50%左右。
三、NLP工程师可以努力的方向
这也是最近讨论比较热烈的一个问题。在我们探讨这个问题之前,可以先思考一下理想的NLP模型应该具有哪些特征。我们认为,比较理想的模型是:
安全可靠/支持长文本/小/快/私有化部署。
所以从个人观点出发,给出一些我们比较关注的方向,抛砖引玉:
1.hallucination
目前LLM最大的问题就是hallucination(hallucination举个例子,就是ChatGPT会一本正经的胡说八道)。那么目前主流两种思路:alignment/多模态。①alignment:alignment就是让模型理解人类语言
声音 | 美联储主席:中美面对CBDC态度有所差异 因为两国制度背景完全不同:美国国会议员比尔·福斯特在今日早些时候举行的货币政策听证会上,对美联储主席杰罗姆·鲍威尔的美国中央银行数字货币(CBDC)进展提出了质疑。在与一些现有的CBDC项目进行比较时,福斯特向鲍威尔提出如何回应中国当前的央行数字货币计划的问题:“您如何形容我们对这种潜在的竞争性威胁做出反应的能力?” 鲍威尔指出,中美面对央行数字货币时有所不同,“它们是完全不同的制度背景。” (cointelegraph)[2020/2/12]
②多模态:多模态是指涉及多个感官或媒体形式的信息处理和表达方式。在自然语言处理和计算机视觉等领域,多模态通常是指同时处理和理解多种输入方式,如文本、音频和图像等。多模态信息处理可以帮助计算机更好地理解复杂的人类交互和情境,从而提高计算机的智能化水平和应用效果。例如,在图像字幕生成任务中,计算机需要同时处理图像和文本,根据图像内容生成相关的文字描述。
Alignment至于如何做alignment,学术界主要是instruction-tuning为主,OpenAI的路线是RLHF,然而普通玩家我是完全不推荐做RL的,只要仔细阅读InstructGPT/GPT-4paper中关于rewardmodel部分就能劝退了。所以对于我们普通玩家,是否有别的路径?多模态GPT4的Paper上看,效果是不错的,不过我们目前还在实践,欢迎实践过的同仁来讨论。2.复现GPT-4/ChatGPT/GPT-3.5/InstructGPT
不开源只能复现,目前主要有(https://github.com/facebookresearch/llama)/(https://huggingface.co/bigscience/bloom)此外还有不开源但是可以使用API访问的百度文心一言/ChatGLM等。
动态 | 面对禁令 印度加密货币交易所Zebpay仍然上线新币种:虽然仍然在和印度央行的禁令做对抗,印度领先的加密货币交易所Zebpay已经在其加密加密交易平台上增加了新的加密货币。该交易所目前支持19种加密货币和超过35种交易对。[2018/7/1]
3.如何评估LLM
很多人提到百度文心一言性能“不够好”,具体指的是哪里不够好?想要回答这个问题,就涉及到:究竟如何量化评估LLM的性能?曾经自动化的方案及Benchmark的参考意义,随着LLM的能力提升显得越来越弱,现在急需新的数据集/评估方案。目前的工作有:(https://github.com/openai/evals)(https://github.com/stanford-crfm/helm)
4.支持长文本
更长的输入,对某些任务是有利的,那么如何让模型支持更长的输入?
主要的思路有两个:
训练时使用较短文本,推理时外推更长的位置信息,使模型获得处理长文本的能力,如bloom中使用的(https://arxiv.org/pdf/2108.12409.pdf)调整模型结构,如最近的工作:(https://arxiv.org/pdf/2303.09752.pdf)PS:GPT-4的输入从GPT-3.5的4K(or8K?)提升到了30K,具体是如何做的呢?
5.变小变快
相同架构的模型通常变小就会变快,让模型变小的方法主要是蒸馏/量化/train小模型,这个方向目前工作有:(https://github.com/tatsu-lab/stanford_alpaca)(https://github.com/TimDettmers/bitsandbytes),中文上也有(https://github.com/THUDM/ChatGLM-6B)/(https://github.com/LianjiaTech/BELLE)等
6.低成本inference
如何在低成本设备上使用这些模型?如单张GPU上跑大模型或普通CPU上跑模型。这个方向的工作也有(https://github.com/FMInference/FlexGen)/(https://github.com/ggerganov/llama.cpp)等。
7.低成本优化
低成本fine-tuning主要有两个方向:①parameter-efficient②sample-efficient.parameter-efficient?的思路目前主要有prompt-tuning/prefix-tuning/LoRA/Adapter等参考(https://github.com/huggingface/peft)
sample-efficient可以帮助我们如何更有效的构造训练集最近的工作有(http://arxiv.org/abs/2303.08114)
8.优化器
优化器决定了我们训练时需要的资源。虽然我们通常使用Adam优化器,但是其需要2倍额外显存,而google好像用Adafactor更多一点,最近他们又出了一个新工作
(https://arxiv.org/abs/2302.06675).9.更可控
如从可控生成角度看,目前可控主要通过controltoken来实现,有没有更好的办法来实现更“精细”的控制?正如controlnet之于stablediffusion。
10.识别AIGC
如何判别内容是人写的还是模型生成的呢?随着模型的性能越来越强,识别AIGC也越来越困难。目前的工作也有watermark/(https://gptzero.me/)等不过我感觉还没什么特别有效的方案目前。对此我有个简单的思路:将AI生成的与非AI生成的看作是两种不同的语言,如code与英语一样,虽然都是相同符号构成,但是对应不同语言。使用大量的AI生成的内容pretrain一个”AI语言模型“,再来进行识别。
11.单一任务/领域刷榜
我认为在某个任务/领域上通过小模型挑战大模型依然有意义,LLM虽然强大,但是依然有太多我们不知道的能力,通过小模型刷榜也许能提供一些思路,就像PET本意是挑战GPT-3,却打开了LLM的新思路。
四、何去何从
1.普通工程师
这种新的革命性的技术我们普通工程师通常都不是第一线的,我们第一次真正使用bert也是在其出来两年后了。即使今天,也有很多场景/公司不使用bert这个技术。换个角度,即使我们想参与,我想能参与训练/fine-tuning一个10B规模模型的工程师都相当少,更别提更大的了。所以到底是“左右逢源”还是“举步维艰”,让子弹飞一会儿吧。
2.普通用户
生活中不缺少美,而是缺少发现美的眼睛。对于普通用户来说,要努力提高自己的鉴别能力
五、番外
1.通过Prompt构建技术壁垒/申请prompt专利
随着alignment的进一步优化,LLM通常越来越理解自然语言,所以我们认为prompt-trick越来越不重要,而清晰地用prompt描述你的需求越来越重要。所谓技术壁垒也许就是如何更清晰有效的描述需求了,但也很难形成技术壁垒。至于专利,软件著作权保护的是制作软件这个技术本身,而非你使用软件时的姿势,所以我想单独的prompt应该也不会形成专利,但是作为你某个技术的一部分,还是有可能的。
2.会不会失业
我们认为不会失业,但会转变一部分人的工作方式。在计算这件事上,人类早已被计算机远远地甩在后面,而计算机的出现也带来了大量的新工作。尤其是LLM现阶段的表现是“懂开车的人才能开车”,所以需要更多更懂某个业务,更熟练使用LLM工具的人。
标签:HTTTPSENTCOMhtt币价格今日行情https://etherscan.ioElementremCOMFY价格
在ChatGPT时代,如何更好的使用AI工具,决定了我们的竞争力,这里汇总我分享过的AI生产力工具.
注:本文来自@youyouAllen推特,MarsBit整理如下:看了孟岩洋洋洒洒几千字,但没有一个清晰结论。我来讲讲web3与GPT的具体结合场景。这里本质上还是底层的区块链与GPT的结合.
前不久,数个顶级的MEV机器人遭到黑客攻击,黑客将MEV机器人的交易包拆解后,将部分交易替换从而盗走了MEV机器人的资金,损失约2500万美元,再度说明了「加密行业是技术人员和黑客的天堂」.
马斯克等千人联名签署公开信《暂停巨型人工智能实验》。具体网页见:https://futureoflife.org/open-letter/pause-giant-ai-experiments/具.
2023香港Web3嘉年华NodeValidatorAsaService专场嘉宾阵容揭晓!共探机遇与未来! 4月13日上午.
明天(4月13日)预计是“合并”之后最受期待的日子。上海升级为以太坊流动性质押的衍生品市场铺平了道路。准备好迎接以太坊世界中的一场改变吧,因为它启用了质押物的提款功能,并彻底改变了LSD市场.