目录
Introduction
中心化元宇宙数据存储现状
Web3驱动的分布式数据存储网络发展现状
分布式存储网络创业公司Mapping?
总结
#Introduction?#
在上一篇《A&T前瞻:为什么Web3驱动的分布式算力网络是元宇宙的基础设施?》里,我们通过收集市场数据和设立假设,论证了为什么Web3驱动的分布式计算是元宇宙时代的基建。在本篇文章里,我们将一起探索在元宇宙时代爆发时,对现在的存储和传输会有什么样的挑战,以及Web3驱动的存储和传输为什么能支撑元宇宙时代的数据量,成为元宇宙时代的基础设施。
#中心化元宇宙数据存储现状#
数据存储,按照存储时长分为两类:
Memory?-内存存储内存里存的数据在计算机关机后将消失,存储在这里的数据是为了加快数据读取速度,或者是为了加快某个计算而暂时性地进行存储。Storage?-硬盘存储存在硬盘存储里的数据不会在计算机关机后消失,会在用户没有直接或间接进行删除操作的情况下永远存储在硬盘里。当用户进行了存储命令操作,一个文件会从内存里复制到硬盘里进行存储。不管是什么数据类型,存在存储介质里的都是一串0和1的数字。在上一篇文章里提到,元宇宙里的沉浸感是由每一帧高清且渲染好的图片通过一个类人眼的显示屏幕展示出来的。在元宇宙里,两个最多的数据类型是音频流和视频流。
现在是怎么做的?
不管是视频流还是音频流,可以分为两大类型:
不需要被处理的数据,这类型数据包括背景音乐、一个场景里的背景某些背景模型等。这类型数据通常被存在本地,需要的时候就可以播出/展示。需要被实时处理的数据,这类型数据包括语音、用户与其他用户互动产生的声音、用户站在不同角度看场景里某个物品。这类型数据需要被处理,如果不是在本地进行处理,则需要在云端或服务器边进行处理并且压缩,然后再传输到客户端边。
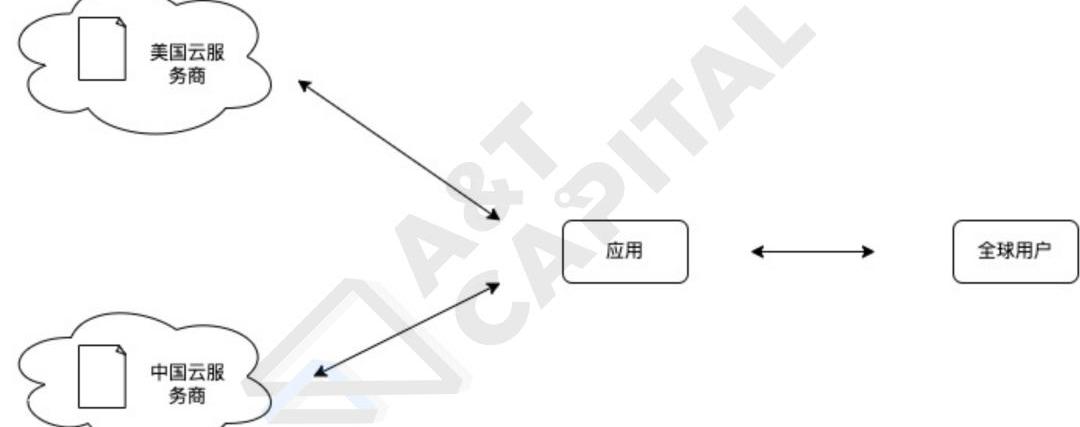
如上图所示,在服务全球用户的时候,同一份数据会被复制到不同的地域的云服务器上,方便就近用户调取文档。虽然云服务看似已经有了巨头公司,但这些云厂商在不同地区的渗透率其实差别很大。例如,AWS在中国的业务渗透率就没有阿里云、腾讯云高。因此,应用在开发时会有以下几个痛点:
单云开发无法满足全球用户需求前面提到,AWS在中国的业务渗透率没有阿里云、腾讯云高。抛开商业和政策角度,国内云厂商在国内设立的数据中心更多、容量更大,能更好的服务国内的用户。这一现象也同样在世界的其他地方发生,因此,在相当一部分的世界里,当地的云厂商在数据中心数量上比起我们知道的云巨头更多,能更好的满足服务当地用户的需求。这一现象给应用开发者带来的难题是,为了更好的服务在不同地区的用户,他们需要将自己的自己的应用需要存储的数据放在当地的云服务厂商的数据中心里,也就是说,他们需要使用多云的存储架构来支持服务全球用户调取数据的需求。多云开发复杂且运维成本高根据上述点一的原因,要满足快速响应全球用户的需求,应用开发者很可能需要使用多云开发的策略。但是,使用多云开发策略是一件复杂且运维起来十分耗时耗人力的事。每家云厂商提供的SDK都不一样,导致即使使用不同云厂商提供的相同的云服务,也会需要通过理解如何使用SDK,如何配置云服务,如何部署等等进行单个云的操作。这样导致使用云的门槛和需要维护系统的人力都需要比使用单云策略更复杂、更高。数据暴露给云厂商,数据没有隐私当将数据存储在云厂商的服务器里的时候,由于明文数据是存储在有能力看到数据的云厂商里,云厂商潜在会去扫描数据,从数据中提取信息,导致数据隐私泄露。数据托管给云厂商,数据也许会丢失与点三的原因相似,由于数据是存储在云厂商的服务器里,云厂商有能力对数据进行更改或者删除,导致数据的完整性缺失,或者是数据的正确性出现问题。未来会有什么痛点?
在上篇《A&T前瞻:为什么Web3驱动的分布式算力网络是元宇宙的基础设施?》文章里有介绍到,想要达到类人眼的的体验,需要向用户输出13k的图片三个颜色的“深浅程度”表示,而每个像素值又占用一个字节。
因此,可以得出一张13k清晰度的图片需要:
13,000*13,000*3=507,000,000字节换算成MB:
507,000,000/1,024,000=~495MB一张压缩后的照片大概能减小~80%的存储需求,那么存储一张压缩后的13k清晰度图片需要占用硬件存储:
495MB*20%=99MB一台自带存储硬件256GB的AR/MR/VR/XR设备只能在本地存储:
256GB*1000/99MB=~2600张13k高清图片一个应用里,尤其是中大型应用,在本地起码需要存储个上万帧图片。在端边设备里可以放置用于存储的硬件是无法随着应用的图像和音频质量的提升而无限增长的,原因在于:
重,所有的AR/MR/VR/XR都在尝试减轻重量,提升用户体验。因此,放太多存储硬件是与这些设备设计方向相违背的。贵,这些设备最终不会靠卖硬件赚钱,而是硬件商通过自家的应用商店向应用开发者收取费用。硬件商会有非常强的意愿控制成本,为的是能大量铺开用户购买来吸引应用开发者,这样应用商店就能赚更多的钱。因此,硬件商不会去加更多存储硬件提升设备成本。因此,光是存一个应用所需的视频即将用满存储,更不用提多个应用需要的常用音频和视频流所需的存储空间。在可预见未来的元宇宙大规模使用后,现在已有的存储架构方式将不足以支撑未来发展需要的数据存储和使用。
#Web3驱动的分布式数据存储网络发展现状#
是什么?
分布式数据存储网络将会存储三种不同类型的数据:
第一类是需要经常被调用的数据/内容,这类数据会存在一个分布式的数据缓存内容分发网络里第二类是非结构化数据,即没有预定义数据模型的数据,不能使用数据库的二维逻辑表进行存储和调取的数据第三类是结构化数据,即有数据模型定义的数据,用数据库的二位逻辑表进行存储和调取的数据在元宇宙里,一些经常需要被调用的视频和音频数据会存储在分布式的数据缓存内容分发网络里,而不常被调用的视频和音频数据则会存储在非结构化数据库里。
每当数据调取的频率发生变化时,分布式的数据缓存内容分发网络里的内容则会随着调用频率而进行更新。
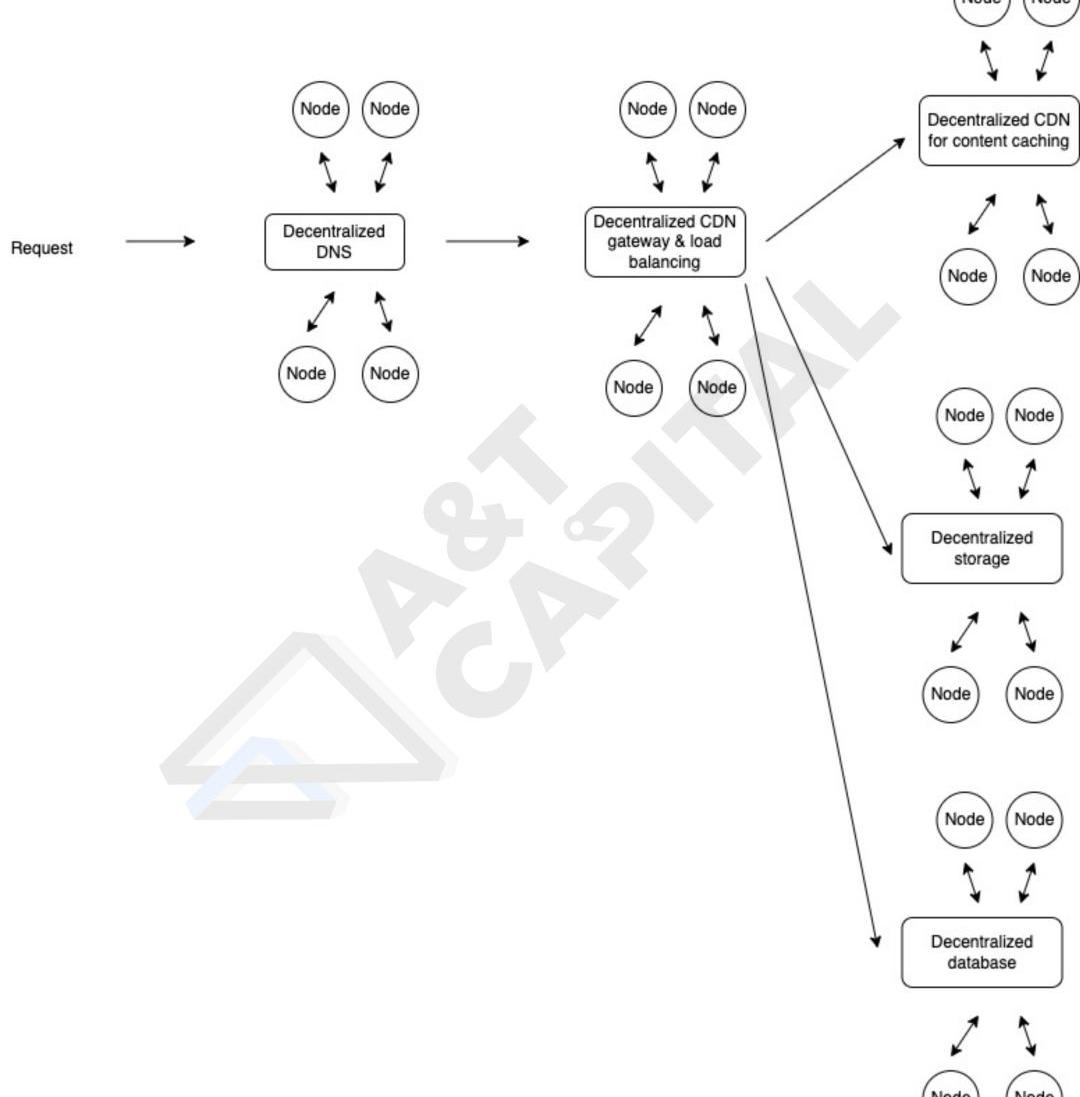
上图展示了一个作者设想的分布式数据存储网络的架构:
一个数据调用的request通过去中心化的dns找到相应的内容分发网络,这一步是为了找到存储request需要调用数据的网络的大致定位;找到网络后,均衡负载和gateway将会把request推送到request想要调取的数据的服务器上。根据数据类型的不同,request可能最终去到:分布式的数据缓存内容分发网络里去中心化非结构数据存储网络里去中心化结构化数据库里如何解决元宇宙里数据隐私、完整性、以及存储调用效率问题?
主动加密/被动加密上文提到的存储数据隐私可能被存储服务器的拥有者侵犯。这一问题可以通过两种方式解决,一个是在数据发送到服务器节点存储时主动进行加密,然后再进行存储。另外一个方式是在数据到达服务器时网络里的其他节点enforce数据必须进行加密后存储。认证节点网络数据的完整性和正确性可以通过一个validatornetwork来确保。validator节点可以periodicallyscan网络节点里的数据,确保没有节点里存储的数据副本一致。节点分布全球存储调用效率与存储距离以及数据存储medium直接相关:当数据存储在内存里,数据在硬件上调取的数据更快;当数据调取的节点离request距离近的话,数据发送的就更快。PoPW使用tokenomics激励全球的网络用户加入数据存储网络,PoPW的共识协议确保数据的正确性和完整性。Tokenomics用于基础设施网络有两个好处:能够在全球范围内快速扩展网络,更好的响应全球的数据调取的需求;大型物理网络需要资金投入,不管是前期购入硬件成本还是后期的运维和维护成本。通过使用tokenomics构建和维护网络并将收益全部分配给供应方是一种更具成本效益的解决方案。#分布式存储网络创业公司Mapping#
Web3驱动的去中心化CDN

Web3驱动的去中心化的非结构性数据存储

Web3驱动的去中心化的关系型数据库
#总结?#
笔者认为,在可预见未来内可以看到web3驱动的分布式节点CDN更大规模的应用、分布式数据库的小规模应用,以及针对非结构化数据存储的优化及潜在小规模应用。
标签:LEX元宇宙比特币WHALEReflex Finance有可能10倍的元宇宙量子比特币创始人Green Whale Challenge
SUI是新一代区块链技术。它是一个去中心化的智能合约平台,自称是Facebook已停运的Libra区块链项目。SUI也是为资产管理创建的低延迟区块链.
基于比特币的L2扩容方案闪电网络最近出现一些新变化,闪电网络开发商LightningLabs发布Taro测试版,允许在其上构建更为丰富的DeFi生态,甚至会促进比特币的进一步主流化.
要点: 吸引散户的新型代币分发机制可以催化牛市,而社交代币就是这样一种分发机制。由于可发现性、用户体验和应用层的问题,WHALE、ALEX和FWB等社交代币过去未能催化出持续的牛市.
10月31日,香港政府发表有关虚拟资产在港发展的政策宣言,引发Web3.0人士广泛讨论。港府新政是否为重大利好?当晚22:00,由香港立法会议员吴杰庄、NanoLabs创始人Jack孔共同发起《.
MarsBitCryptoDaily2022年10月19日 一、今日要闻 公链Sui品牌将升级为Suinami据官方消息,公链Sui宣布品牌将升级为Suinami.
区块链开始扩展时会发生什么?你会遇到数据可用性的问题。我们来分析一下它是什么,以及@CelestiaOrg是如何在可扩展数据层架构上进行创新的.